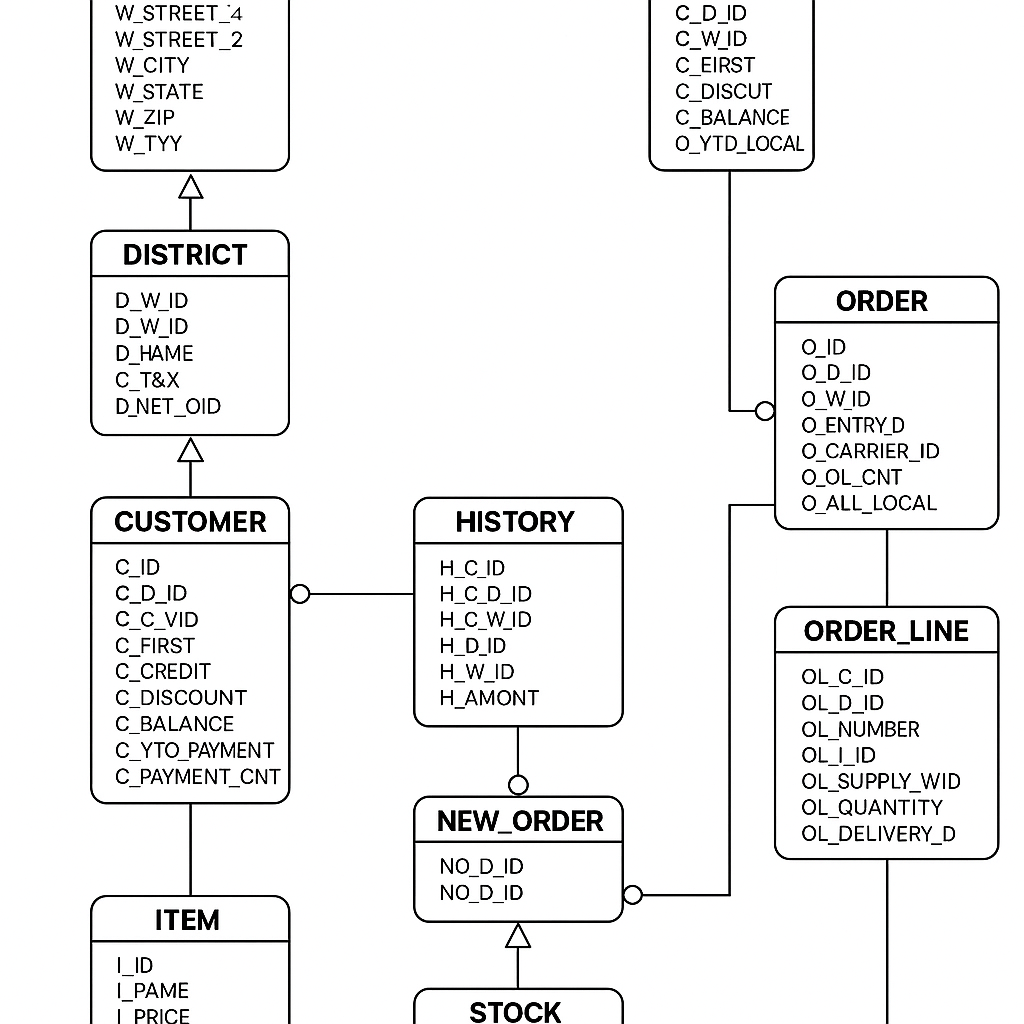
TPCC
- ER digram:
pgbench is a benchmarking tool bundled with PostgreSQL, designed to simulate a TPC-B-like workload, not a full TPC-C
This sets up the schema and populates data.
1 | pgbench -i -s 10 mydb |
1 | pgbench -c 10 -j 2 -T 60 mydb |
It will output something like:
1 | [postgres@iZ2ze4mflpfiplp0evcw8gZ root]$ pgbench -c 10 -j 2 -T 60 mydb |
You can benchmark with custom SQL transactions:
1 | pgbench -f myscript.sql -c 10 -T 60 mydb |
Where myscript.sql contains something like:
1 | BEGIN; |
Use :variable for substitution. We can define variables using -D:
1 | pgbench -f myscript.sql -D aid=12345 -D delta=50 -c 10 -T 60 mydb |
要在发生故障后恢复数据一致性(即执行恢复操作),PostgreSQL 需要向前回放 WAL 日志,并将其中表示丢失变更的记录应用到相应的数据页上。为了确定哪些变更丢失了,系统会将磁盘上数据页的 LSN(日志序列号)与 WAL 记录的 LSN 进行比较。但问题是,我们应该从哪里开始恢复?如果恢复起点选得太晚,那么在此之前已经写入磁盘的数据页将无法接收到所有应有的变更,最终导致无法修复的数据损坏。而从日志的起始位置开始恢复又不现实:不仅无法长期保存如此巨量的数据,也无法接受过长的恢复时间。因此,我们需要一个不断向前推进的检查点(checkpoint),从而可以从这个位置安全地开始恢复,同时删除所有更早的 WAL 记录。
创建检查点最直接的方式是:定期暂停系统所有操作,并将所有脏页强制刷新到磁盘。但这种方式显然是不可接受的,因为系统会因此暂停不定但相当长的时间。
正因为如此,PostgreSQL 将检查点的过程分摊到一段时间内完成,实际上构成了一个“区间”(interval)。检查点的执行是由一个特殊的后台进程负责的,这个进程叫做 checkpointer(检查点进程)
checkpointer 进程会将所有可以立即写入磁盘的内容进行刷新,包括:
检查点执行的大部分时间都耗费在将 脏页(dirty pages)刷新到磁盘上。
首先,在检查点开始时,所有当时处于“脏”状态的缓冲区(buffer)的页头会被打上一个特殊标记(tag)。这个过程非常迅速,因为它不涉及任何 I/O 操作,只是内存中的标记设置。
随后,checkpointer 会遍历所有缓冲区,并将带有该标记的页写入磁盘。这些页不会被驱逐出缓存(即它们仍然保留在缓冲池中),只是被刷盘,因此在这个过程中可以忽略使用计数(usage count)和 pin 计数(pin count)。
页面按 ID 顺序处理,以尽可能避免随机写入。为实现更好的负载均衡,PostgreSQL 会在多个表空间之间交替进行写入(因为它们可能位于不同的物理设备上)。
后端进程(backend)也可以将打了标记的缓冲页写入磁盘 —— 如果它们先访问到了这些页的话。无论由谁写入,缓冲区的标记都会在这个阶段被清除,因此每个缓冲页在此次检查点中只会被写一次。
很自然地,在 checkpoint 进行期间,缓冲区中的页面仍然可能被修改。但由于这些新的脏页没有被打上标记,checkpointer 会忽略它们。
当在检查点开始时被标记为脏的所有缓冲页都已经写入磁盘后,检查点就被视为完成。从现在起(但不是在此之前!),本次检查点的起始位置将被作为恢复操作的新起点。在这个点之前写入的所有 WAL 日志都不再需要了。
1 | Time → |
最后,checkpointer 进程会创建一条表示检查点完成的 WAL 记录,并在其中标明此次检查点的起始 LSN。由于检查点在开始时不会写入任何日志,因此这个起始 LSN 可以是任意类型的 WAL 记录所属的 LSN。
此外,PGDATA/global/pg_control 文件也会被更新,以指向最近完成的检查点。(在此过程完成之前,pg_control 始终保留着上一个检查点的信息。)
Example:
1 | => UPDATE big SET s = 'FOO'; |
最新的 WAL 条目与检查点完成有关(CHECKPOINT_ONLINE)。该检查点的起始 LSN 出现在 redo 之后;这个位置对应的是检查点开始时最新插入的 WAL 条目。
同样的信息也可以在 pg_control 文件中找到。
1 | postgres$ /usr/local/pgsql/bin/pg_controldata \ |
ASan 是 GCC 和 Clang 内建的功能,无需额外安装 ASan,只需要你的编译器支持即可。GCC ≥ 4.8 / Clang ≥ 3.1 就支持 ASan
1
2
3
4
5
6
7
8
9
10
11
root@lavm-bar1guved6:~# clang --version
Ubuntu clang version 14.0.0-1ubuntu1.1
Target: x86_64-pc-linux-gnu
Thread model: posix
InstalledDir: /usr/bin
root@lavm-bar1guved6:~# gcc --version
gcc (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0
Copyright (C) 2021 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE
1
gcc -fsanitize=address -g your_file.c -o your_program
1
2
3
4
5
6
7
8
9
10
11
12
13
# 编译阶段(C/C++)加 ASan 插桩
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -fsanitize=address -fno-omit-frame-pointer -g")
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -fsanitize=address -fno-omit-frame-pointer -g")
# 链接阶段链接 libasan
set(CMAKE_EXE_LINKER_FLAGS "${CMAKE_EXE_LINKER_FLAGS} -fsanitize=address")
set(CMAKE_SHARED_LINKER_FLAGS "${CMAKE_SHARED_LINKER_FLAGS} -fsanitize=address")
#or
cmake -DCMAKE_C_FLAGS="-fsanitize=address -fno-omit-frame-pointer -g" \
-DCMAKE_EXE_LINKER_FLAGS="-fsanitize=address" \
-DCMAKE_BUILD_TYPE=Debug \
......
可以在 CFLAGS 中添加:
1 | CFLAGS += -fsanitize=address -g -fno-omit-frame-pointer |
GCC 和 Clang 中 ASan 自动包含 LeakSanitizer(LSan),但某些情况下要确保:
1 | -fsanitize=address -fno-omit-frame-pointer |
加上 -fno-omit-frame-pointer 可以让调用栈更完整。
编译好的程序可以直接运行:
1 | ./your_program |
1 | export ASAN_OPTIONS=detect_leaks=1:halt_on_error=0:symbolize=1:quarantine_size=1024:log_path=/home/postgres/asan/asan.log |
1 | ================================================================= |
在发生故障(例如停电、操作系统错误或数据库服务器崩溃)时,RAM 中的所有内容都将丢失;只有写入磁盘的数据会保留下来。要在故障后启动服务器,您必须恢复数据一致性。如果磁盘本身已损坏,则必须通过备份恢复来解决相同的问题。
理论上,您可以始终保持磁盘上的数据一致性。但实际上,这意味着服务器必须不断地将随机页面写入磁盘(尽管顺序写入成本更低),并且此类写入的顺序必须保证在任何特定时刻都不会损害一致性(这很难实现,尤其是当您处理复杂的索引结构时)。
与大多数数据库系统一样,PostgreSQL 采用了一种不同的方法。
服务器运行时,部分当前数据仅存在于 RAM 中,其写入永久存储的操作被推迟。因此,服务器运行时存储在磁盘上的数据始终是不一致的,因为页面从不会一次性全部刷新。但是,RAM 中发生的每个更改(例如在缓冲区缓存中执行的页面更新)都会被记录下来:PostgreSQL 会创建一个日志条目,其中包含在需要时重复此操作所需的所有基本信息。
页面修改相关的日志条目必须先于修改后的页面本身写入磁盘。这就是日志名称的由来:预写式日志(write-ahead log),简称 WAL。这项要求保证了在发生故障时,PostgreSQL 可以从磁盘读取 WAL 条目并重放它们,以重复那些已完成但结果仍在 RAM 中且在崩溃前未写入磁盘的操作。
保留预写式日志通常比将随机页面写入磁盘更高效。WAL 条目构成一个连续的数据流,即使是硬盘驱动器 (HDD) 也能很好地处理。此外,WAL 条目通常比页面大小更小。
为了在发生故障时避免数据不一致,所有可能破坏数据一致性的操作都需要记录下来。具体来说,以下操作会记录在 预写式日志 (WAL) 中:
在 PostgreSQL 10 之前,哈希索引的操作也不会被记录。它们的主要目的是将哈希函数与不同的数据类型匹配。
除了用于崩溃恢复之外,WAL 还可以用于从备份进行时间点恢复以及数据复制。
Raft 是一个分布式一致性算法,被设计为比 Paxos 更易于理解,同时具备相似的性能和安全性。它常用于构建容错的分布式系统,确保多个节点在面对网络分区、节点失效等情况下能够达成一致
MultiRaft 是 Raft 的一种扩展,旨在支持多个 Raft 实例同时运行,以便在大规模分布式系统中更高效地管理数据分片和分布式事务。
| 特性 | Raft | MultiRaft |
|---|---|---|
| 目标 | 提供单一一致性机制 | 提供分区一致性机制 |
| 运行实例 | 单个 Raft 集群 | 多个独立的 Raft 集群 |
| 适用场景 | 小规模系统 | 大规模分布式存储或事务场景 |
| 扩展性 | 有限,单点可能成为瓶颈 | 高扩展性,分片机制避免瓶颈 |
| 复杂度 | 较低 | 较高,需要处理跨分片事务 |
If bulk reads or writes are performed, there is a risk that one-time data can quickly oust useful pages from the buffer cache.
As a precaution, bulk operations use rather small buffer rings, and eviction is performed within their boundaries, without affecting other buffers.
A buffer ring of a particular size consists of an array of buffers that are used one after another. At first, the buffer ring is empty, and individual buffers join it one by one, after being selected from the buffer cache in the usual manner. Then eviction comes into play,but only within the ring limits
Buffers added into a ring are not excluded from the buffer cache and can still be used by other operations. So if the buffer to be reused turns out to be pinned, or its usage count is higher than one, it will be simply detached from the ring and replaced by another buffer.
PostgreSQL supports three eviction strategies.
| strategy | trigger | buffer ring |
|---|---|---|
| Bulk reads | sequential scans of large tables if their size exceeds 1/4 of the buffer cache(128MB:16384 page) | 256KB(32 page) |
| Bulk writes | applied by Copy from, create table as select , and create materialized view commands, as well as by those alter table flavors that cause table rewrites. | default: 16MB(2048 page) |
| Vacuuming | full table scan without taking the visibility map into account | 256KB(32 page) |
Buffer rings do not always prevent undesired eviction. If UPDATE or DELETE commands affect a lot of rows, the performed table scan applies the bulk reads strategy, but since the pages are constantly being modified, buffer rings virtually become useless.
Another example worth mentioning is storing oversized data in TOAST tables. In spite of a potentially large volume of data that has to be read, toasted values are always accessed via an index, so they bypass buffer rings.
Let’s take a closer look at the bulk reads strategy. For simplicity, we will create a table in such a way that an inserted row takes the whole page. By default, the buffer cache size is 16,384 pages, 8 kb each. So the table must take more than 4096 pages for the scan to use a buffer ring.
1 | test=# SHOW shared_buffers; |
x (examine) 命令允许你检查内存中的数据。你可以指定要检查的内存地址、格式和单位。
基本语法: x /nfu addr
n:要显示的单位数量。
f:显示格式(例如,x 表示十六进制,t 表示二进制,d 表示十进制)。
u:单位大小(b 表示字节,h 表示半字(16 位),w 表示字(32 位),g 表示巨字(64 位))。
addr:要检查的内存地址。
示例: 假设有一个 32 位整数 val,其地址为 0x12345678,你想以 16 位为单位查看:
1 | x /2ht 0x12345678 |
这将显示从 0x12345678 开始的两个半字(16 位)的十六进制值。
结合 p 命令获取地址: 你可以使用 p &变量名 获取变量的地址,然后将其传递给 x 命令。
1 |
|
编译并用 GDB 调试:
1 | gcc -g test.c -o test |
在 GDB 中:
1 | (gdb) break main |
这里注意字节序,在小端序机器上,低位字节在前,高位字节在后,所以显示为 0x5678 0x1234。
如果想要二进制显示,则使用:
1 | x /2ht 0x7fffffffe0dc |
如果你只想查看变量的值,而不需要查看内存,可以使用 C 语言的位运算来提取 16 位部分,然后使用 p/t 显示。
示例:
1 | int val = 0x12345678; |
在 GDB 中:
1 | (gdb) p/t (val & 0xFFFF) // 获取低 16 位 |
对于查看内存中的数据(包括变量在内存中的表示),使用 x 命令结合 h (半字) 和 t (二进制) 格式指定符是最直接的方法。
对于只查看变量的值,使用位运算提取 16 位部分,然后使用 p/t 也是一个有效的选择。
选择哪种方法取决于你的具体需求。如果你需要查看变量在内存中的布局(例如,在结构体或数组中),x 命令是更好的选择。如果你只需要查看变量值的不同部分,位运算可能更方便。
1 | set target-async 1 |
路径完全匹配(核心条件)
GDB 的自动加载逻辑非常死板,它会根据你的程序链接的 libstdc++.so.6 的真实物理路径来拼接查找路径。
如果你的程序链接的是 /usr/lib64/libstdc++.so.6,那么 GDB 会尝试在以下位置查找: [auto-load 根目录] + [库的绝对路径] + [-gdb.py 脚本]
即:/usr/share/gdb/auto-load + /usr/lib64/libstdc++.so.6 + -gdb.py 也就是你找到的:/usr/share/gdb/auto-load/usr/lib64/libstdc++.so.6-gdb.py。
必须开启 safe-path 权限
即使文件位置对了,GDB 为了安全默认也是不运行它的。你需要给它“授权”。
1 | set auto-load safe-path / |
start gdb:
1 | info auto-load python-scripts |