Predicate_locks_in_pg
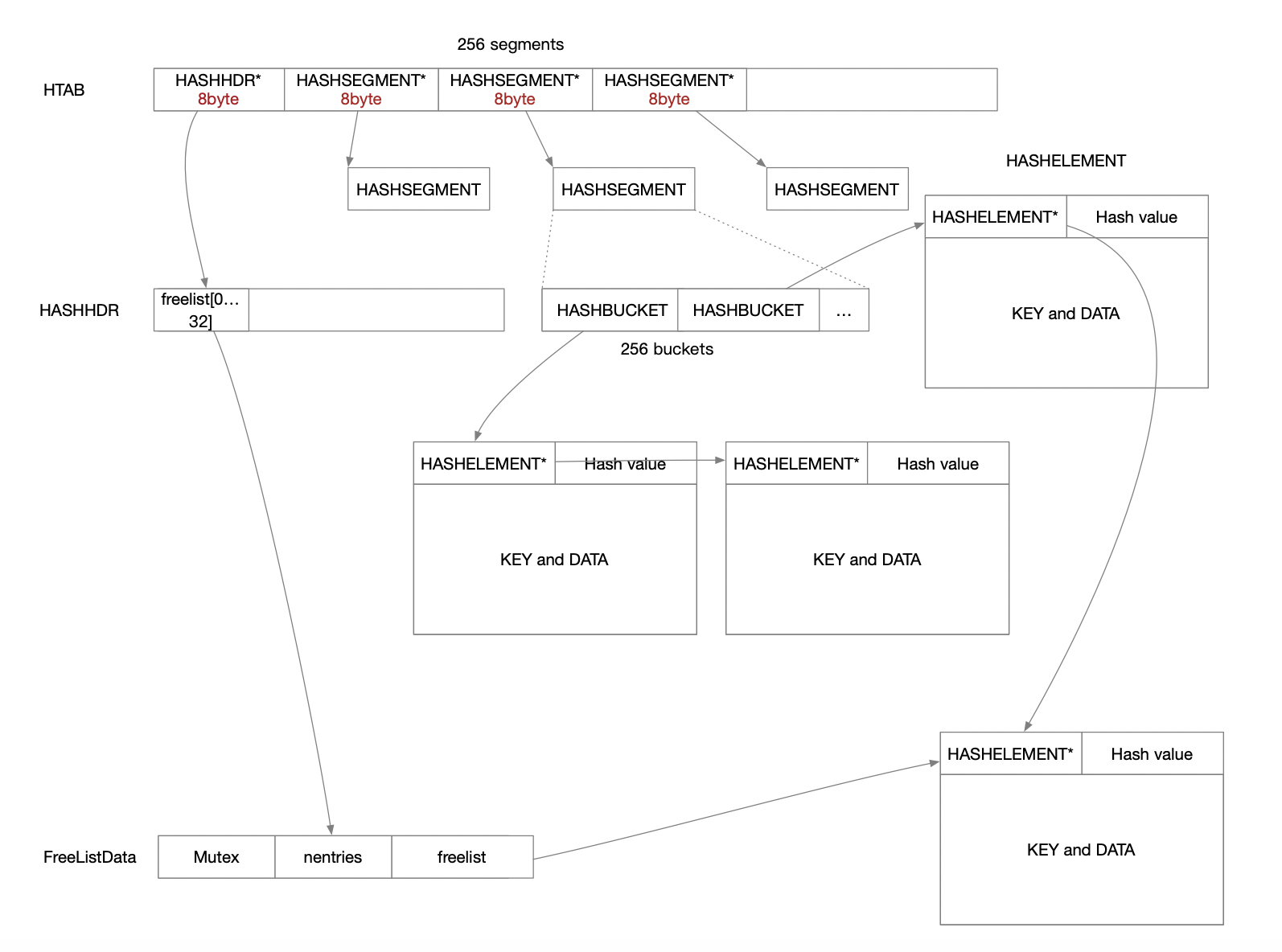
谓词锁:
- 传统谓词锁:
- 真锁:锁住一个数学条件(如 age > 10)。
- 缺点:
- 数据库难以判断任意两个条件是否重叠(数学上不可判定)
- 性能极差
- postgresql谓词锁:
- 假锁,实际上是标记(SIRead 标记)。
- 目的:支持 SSI(可串行化快照隔离)协议。
- 本质:在内存中不阻塞任何事务,只做“记事本”,记录谁读了什么,谁后来改了什么。
为什么记录 RW(读后写)依赖?
- 写偏斜(Write Skew)最难防。
- 常规锁只能解决 WR 依赖(先写后读)。
- 对 RW 依赖(先读后写),普通锁无法察觉
PostgreSQL 的解决方法
- 事务 A 读数据 → 默默加 SIRead 标记。
- 事务 B 修改数据 → 检查 SIRead 标记 → 在后台依赖图上连线(A →rw B)
An Example
让我们创建一个具有跨多个页面的索引的表(可以通过使用较低的填充因子值来实现):
1 | CREATE TABLE pred(n numeric, s text); |
如果查询执行顺序扫描,则会在整个表上获取谓词锁(即使某些行不满足提供的过滤条件)。
Sequential scan 丢失了谓词的精度,PG 只能保守地锁整表。这是一种宁可误判、不能漏判的策略——牺牲并发性,换取正确性。
1 | mytest=# SELECT pg_backend_pid(); |
尽管谓词锁(predicate locks)拥有自己独立的底层基础设施,但 pg_locks 视图仍然会将它们与重量级锁(heavyweight locks)放在一起共同显示。所有的谓词锁在获取时,其模式一律为 SIRead 模式,该模式是“可串行化隔离读”(Serializable Isolation Read)的缩写。
1 | mytest=*# SELECT relation::regclass, locktype, page, tuple FROM pg_locks WHERE mode = 'SIReadLock' AND pid = 512701 ORDER BY 1, 2, 3, 4; |
需要注意的是,谓词锁的持有时间可能会超过事务本身的持续时间,因为它们被用来追踪事务之间的依赖关系。但无论如何,它们都是自动管理的。
如果查询执行的是索引扫描(index scan),情况就会有所好转。对于 B-tree 索引,只需在读取的堆元组(heap tuples,即实际的数据行)以及索引中被扫描的叶子页面(leaf pages)上设置谓词锁即可。这将“锁定”已被读取的整个范围,而不仅仅是那些精确的数值。
1 | mytest=# BEGIN ISOLATION LEVEL SERIALIZABLE; |
已经扫描过的元组(数据行)所对应的索引叶子页面(leaf pages)数量是会发生变化的:例如,当向表中插入新行时,索引页面可能会发生分裂(split)。然而,PostgreSQL 充分考虑到了这种情况,并且也会将新出现的页面锁定
1 | mytest=*# SELECT relation::regclass, locktype, page, tuple FROM pg_locks WHERE mode = 'SIReadLock' AND pid = 512701 ORDER BY 1, 2, 3, 4; |
每一个被读取的元组(数据行)都是被单独锁定的,而这类元组的数量可能会相当庞大。谓词锁使用在服务器启动时分配的独立内存池。谓词锁的总数受到 max_pred_locks_per_transaction 参数值乘以 max_connections 参数值的限制(尽管从参数名称来看,谓词锁并不是按每个独立事务分别计算的)
在这里,我们遇到了与行级锁(row-level locks)相同的问题,但解决方式却截然不同:这里应用了“锁升级”(lock escalation)机制。
一旦与单个页面(page)相关的元组锁(tuple locks)数量超过了 max_pred_locks_per_page 参数的值(默认值设为 2),它们就会被一个单一的页面级锁(page-level lock)所取代
1 | mytest=*# EXPLAIN (analyze, costs off, timing off, summary off) SELECT * FROM pred WHERE n BETWEEN 1000 AND 1002; |
现在,我们不再拥有三个元组类型的锁,而是拥有了一个页面类型的锁:
1 | mytest=*# SELECT relation::regclass, locktype, page, tuple FROM pg_locks WHERE mode = 'SIReadLock' AND pid = 512701 ORDER BY 1, 2, 3, 4; |
锁升级肯定会导致误报序列化错误,这会对系统吞吐量产生负面影响。因此,必须在性能和在锁上花费可用资源之间找到适当的平衡。
Predicate locks 支持以下索引类型:
- B-Trees
- hash indexes, GiST, and GIN
如果执行索引扫描,但索引不支持谓词锁,则整个索引将被锁定。可以预见的是,在这种情况下,无故中止的事务数量也会增加。
为了在可串行化(Serializable)级别下实现更高效的运行,通过 READ ONLY 子句将事务显式声明为“只读”是非常有意义的。如果锁管理器(lock manager)发现一个只读事务不会与其他事务发生冲突,它就可以释放已经设置的谓词锁,并且不再获取新的谓词锁。而如果这样的事务同时被声明为 DEFERRABLE(可延迟的),那么只读事务异常(read-only transaction anomaly)也将得以避免。