=>CREATE INDEX ON bookings(total_amount); => EXPLAIN SELECT* FROM bookings WHERE total_amount >1000000; QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Bitmap Heap Scan on bookings (cost=86.49..9245.82rows=4395 wid... Recheck Cond: (total_amount >'1000000'::numeric) −> Bitmap Index Scan on bookings_total_amount_idx (cost=0.00.... Index Cond: (total_amount >'1000000'::numeric) (4rows)
但如果给定的条件对所有预订记录都成立,那么使用索引就没有意义了,因为最终仍然需要扫描整张表。
1 2 3 4 5 6 7
=> EXPLAIN SELECT* FROM bookings WHERE total_amount >100; QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Seq Scan on bookings (cost=0.00..39835.88rows=2111110 width=21) Filter: (total_amount >'100'::numeric) (2rows)
=>BEGIN; =>DECLARE cur CURSORFORSELECT* FROM aircrafts ORDERBY aircraft_code; =>FETCH3FROM cur; aircraft_code | model |range −−−−−−−−−−−−−−−+−−−−−−−−−−−−−−−−−+−−−−−−− 319| Airbus A319−100|6700 320| Airbus A320−200|5700 321| Airbus A321−200|5600 (3rows) =>FETCH2FROM cur; aircraft_code | model |range −−−−−−−−−−−−−−−+−−−−−−−−−−−−−−−−+−−−−−−− 733| Boeing 737−300|4200 763| Boeing 767−300|7900 =>COMMIT; (2rows)
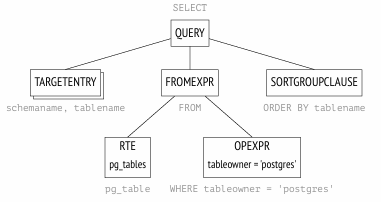
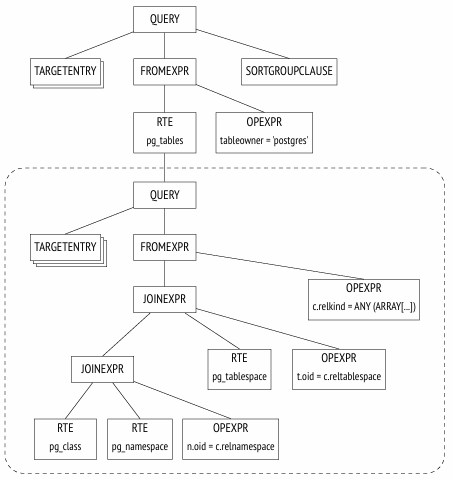
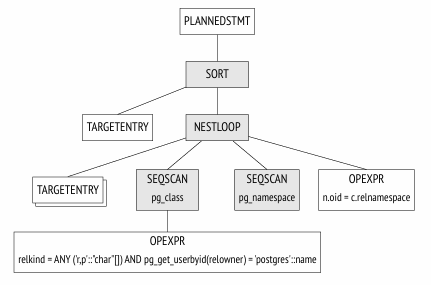
SELECT schemaname, tablename FROM (-- pg_tables SELECT n.nspname AS schemaname, c.relname AS tablename, pg_get_userbyid(c.relowner) AS tableowner, ... FROM pg_class c LEFTJOIN pg_namespace n ON n.oid = c.relnamespace LEFTJOIN pg_tablespace t ON t.oid = c.reltablespace WHERE c.relkind =ANY (ARRAY['r'::char, 'p'::char]) ) WHERE tableowner ='postgres' ORDERBY tablename;
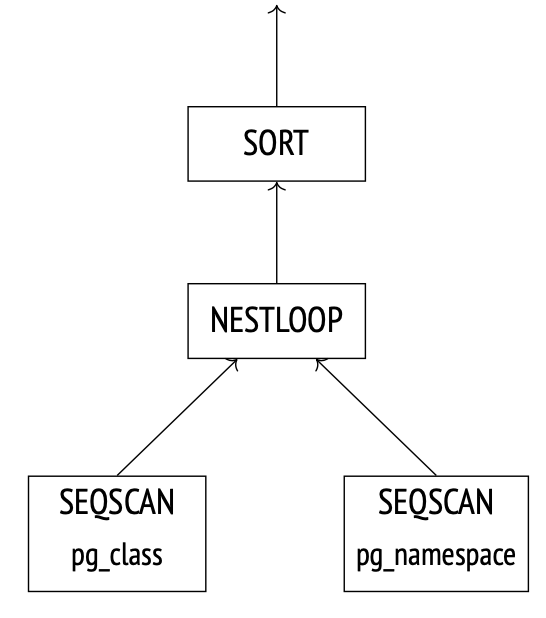
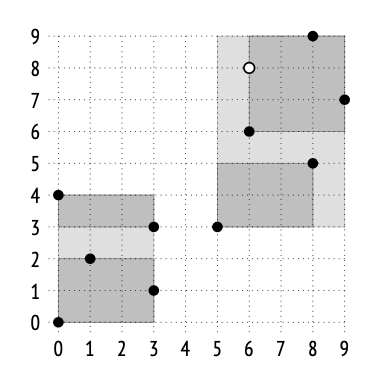
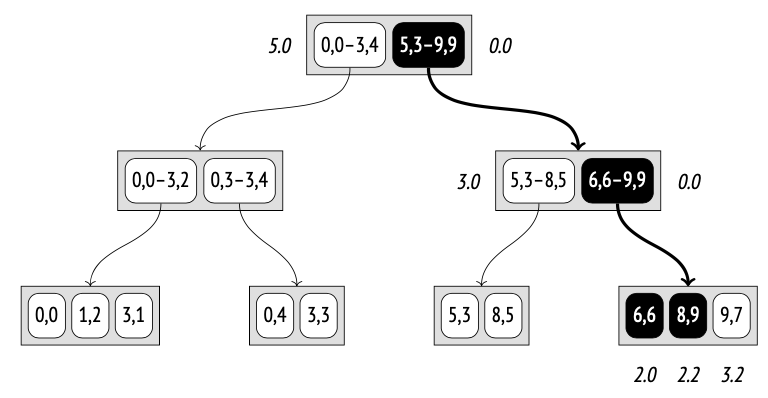
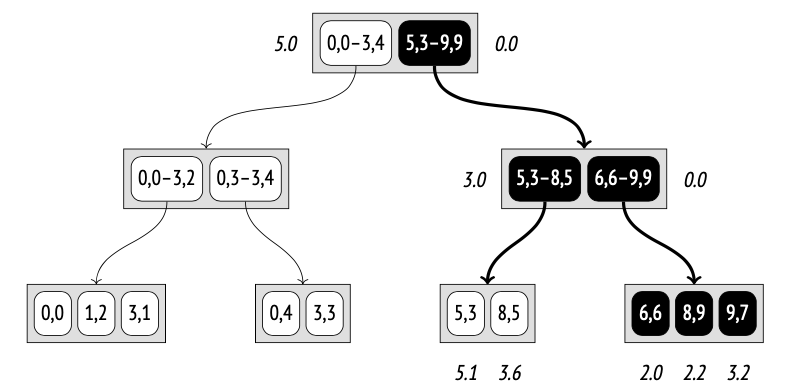
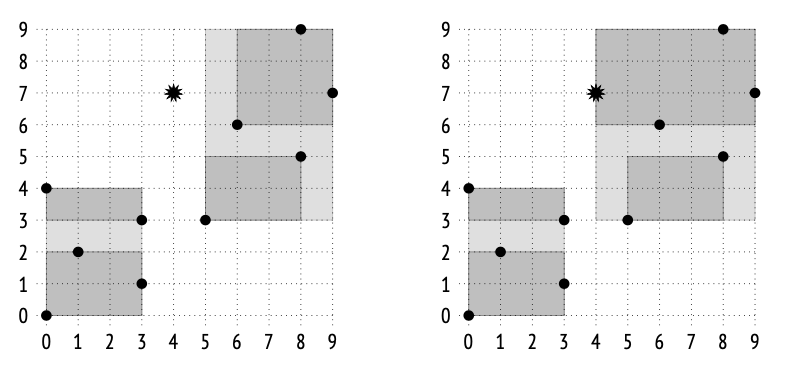
Plan search PostgreSQL 使用的是基于成本(cost-based)的优化器;它会遍历可能的执行计划,并估算执行这些计划所需的资源,例如 I/O 操作或 CPU 周期。这种估算会被归一化为一个数值,称为该计划的 cost(成本)。在所有被考虑的计划中,优化器最终会选择 成本最低的那个计划。
sel_X:满足条件 X 的行比例 sel_Y:满足条件 Y 的行比例 条件 X AND Y:满足两个条件的行,概率就是两者独立事件概率的乘积; (1 - sel_X):不满足 X 的行比例, (1 - sel_Y):不满足 Y 的行比例, (1 - sel_X)(1 - sel_Y):同时不满足 X 和 Y 的行比例.所以 1 − (1 − sel_X)(1 − sel_Y) = 满足 X 或 Y 的行比例
不幸的是,上述公式假设谓词 X 和 Y 彼此独立。对于相关(correlated)的谓词,这类估算将不准确。
demo=# SET default_text_search_config = english; SET demo=# SELECT to_tsvector( 'No one can tell me, nobody knows, '|| 'Where the wind comes from, where the wind goes.' ); to_tsvector ---------------------------------------------------------------------- 'come':11'goe':16'know':7'nobodi':6'one':2'tell':4'wind':10,15 (1row)
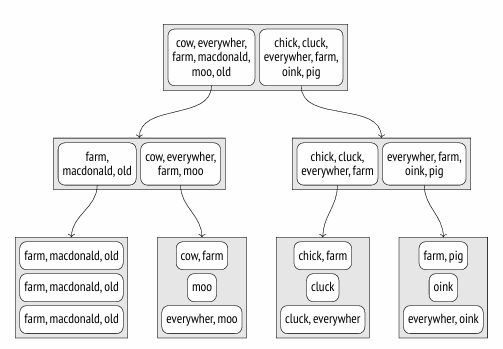
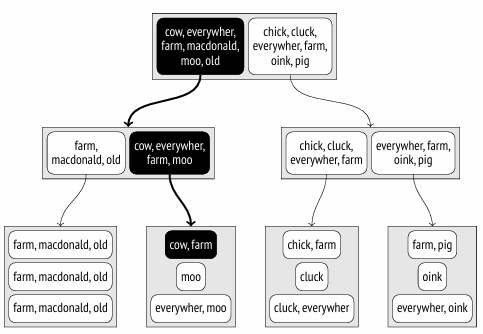
demo=# INSERT INTO ts(doc) VALUES ('Old MacDonald had a farm'), ('And on his farm he had some cows'), ('Here a moo, there a moo'), ('Everywhere a moo moo'), ('Old MacDonald had a farm'), ('And on his farm he had some chicks'), ('Here a cluck, there a cluck'), ('Everywhere a cluck cluck'), ('Old MacDonald had a farm'),('And on his farm he had some pigs'), ('Here an oink, there an oink'),('Everywhere an oink oink') RETURNING doc_tsv; doc_tsv -------------------------------- 'farm':5'macdonald':2'old':1 'cow':8'farm':4 'moo':3,6 'everywher':1'moo':3,4 'farm':5'macdonald':2'old':1 'chick':8'farm':4 'cluck':3,6 'cluck':3,4'everywher':1 'farm':5'macdonald':2'old':1 'farm':4'pig':8 'oink':3,6 'everywher':1'oink':3,4 (12rows)
ALTER TABLE mail_messages ADDCOLUMN tsv tsvector GENERATED ALWAYS AS ( to_tsvector( 'pg_catalog.english', subject||' '||author||' '||body_plain ) ) STORED; NOTICE: word is too long to be indexed DETAIL: Words longer than 2047 characters are ignored. ... NOTICE: word is too long to be indexed DETAIL: Words longer than 2047 characters are ignored. ALTER TABLE
CREATE INDEX mail_gist_idx ON mail_messages USING gist(tsv); SELECT pg_size_pretty(pg_relation_size('mail_gist_idx')); pg_size_pretty −−−−−−−−−−−−−−−− 127 MB (1row)
demo=# DROP INDEX mail_messages_tsv_idx; DROP INDEX demo=# CREATE INDEX ON mail_messages USING gist(tsv tsvector_ops(siglen=1024)); CREATE INDEX demo=# SELECT pg_size_pretty(pg_relation_size('mail_messages_tsv_idx')); pg_size_pretty ---------------- 241 MB (1row)
demo=# EXPLAIN (analyze, costs off, timing off, summary off) SELECT* FROM mail_messages WHERE tsv @@ to_tsquery('magic & value'); QUERY PLAN ------------------------------------------------------------------------------ Index Scan using mail_gist_idx on mail_messages (actual rows=898.00 loops=1) Index Cond: (tsv @@ to_tsquery('magic & value'::text)) Rows Removed by Index Recheck: 7852 Index Searches: 1 Buffers: shared hit=25968 read=33482 Planning: Buffers: shared hit=3 read=2 dirtied=1 (7rows)
demo=# CREATE TABLE airports_big ASselect*from airports_data; SELECT104 demo=# COPY airports_big FROM'/home/postgres/data/extra_airports.copy'; COPY5413 demo=# CREATE INDEX airports_gist_idx ON airports_big USING gist(coordinates) WITH (fillfactor=10); CREATE INDEX
To extract more detailed information, you can use the gevel extension,which is not included into the standard PostgreSQL distribution.
Operator Class
This query retrieves the list of support functions used by the point_ops operator class in a GiST (Generalized Search Tree) index within a PostgreSQL database
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
demo=# SELECT amprocnum, amproc::regproc FROM pg_am am JOIN pg_opclass opc ON opcmethod = am.oid JOIN pg_amproc amop ON amprocfamily = opcfamily WHERE amname ='gist' AND opcname ='point_ops' ORDERBY amprocnum; amprocnum | amproc -----------+------------------------ 1| gist_point_consistent 2| gist_box_union 3| gist_point_compress 5| gist_box_penalty 6| gist_box_picksplit 7| gist_box_same 8| gist_point_distance 9| gist_point_fetch 11| gist_point_sortsupport (9rows)
必需的函数:
1 consistency function used to traverse the tree during search(检查查询条件是否与索引条目一致)
2 union function that merges rectangles计算边界框的并集)
5 penalty function used to choose the subtree to descend to when inserting an entry (计算插入新条目的代价)
6 picksplit function that distributes entries between new pages after a page split(决定节点分裂方式)
7 same function that checks two keys for equality(比较索引条目是否相同)
demo=# SELECT airport_code, airport_name->>'en' FROM airports_big WHERE coordinates <@ '<(37.622513,55.753220),1.0>'::circle; airport_code | ?column? --------------+------------------------------------ SVO | Sheremetyevo International Airport VKO | Vnukovo International Airport DME | Domodedovo International Airport BKA | Bykovo Airport ZIA | Zhukovsky International Airport CKL | Chkalovskiy Air Base OSF | Ostafyevo International Airport (7rows)
demo=# EXPLAIN (costs off) SELECT airport_code FROM airports_big WHERE coordinates <@ '<(37.622513,55.753220),1.0>'::circle; QUERY PLAN ------------------------------------------------------------------------- Bitmap Heap Scan on airports_big Recheck Cond: (coordinates <@ '<(37.622513,55.75322),1>'::circle) -> Bitmap Index Scan on airports_gist_idx Index Cond: (coordinates <@ '<(37.622513,55.75322),1>'::circle) (4rows)
demo=# SELECT amopopr::regoperator, amoppurpose, amopstrategy FROM pg_am am JOIN pg_opclass opc ON opcmethod = am.oid JOIN pg_amop amop ON amopfamily = opcfamily WHERE amname ='gist' AND opcname ='point_ops' ORDERBY amopstrategy; amopopr | amoppurpose | amopstrategy -------------------+-------------+-------------- <<(point,point) | s |1 >>(point,point) | s |5 ~=(point,point) | s |6 <<|(point,point) | s |10 |>>(point,point) | s |11 <->(point,point) | o |15 <@(point,box) | s |28 <^(point,point) | s |29 >^(point,point) | s |30 <@(point,polygon) | s |48 <@(point,circle) | s |68 (11rows)
尝试创建这样的约束会导致一个错误,因为对于 text 数据类型并没有可用的操作符类(operator class)。
1 2 3 4 5 6 7 8 9
demo=# ALTER TABLE airports_data DROPCONSTRAINT airports_data_circle_excl; ALTER TABLE demo=# ALTER TABLE airports_data ADD EXCLUDE USING gist ( circle(coordinates,0.2) WITH&&, (city->>'en') WITH!= ); ERROR: data type text has nodefault operator class for access method "gist" HINT: You must specify an operator class for the index ordefine a default operator class for the data type. demo=#
虽然 GiST 原生不支持 text 或 int 等有序类型,但借助 btree_gist 扩展,可以让这些类型也具备使用 GiST 进行等值/比较操作的能力,从而用于复杂约束(如排除约束)或混合类型索引。
1 2 3 4 5 6 7
demo=# CREATE EXTENSION btree_gist; CREATE EXTENSION demo=# ALTER TABLE airports_data ADD EXCLUDE USING gist ( circle(coordinates,0.2) WITH&&, (city->>'en') WITH!= ); ALTER TABLE demo=#
Lehman–Yao构造了一个供并发进程使用的数据结构。该数据结构是 Wedekind提出的 B*-树的一个简单变体(其基础是 Bayer 和 McCreight定义的 B 树)。 Lehman–Yao B*-树定义如下。
1.1 定义
Each path from the root to any leaf has the same length, h.
内部节点(非 root、非叶子)至少要有 k + 1 个孩子(sons)。 (k is a tree parameter; 2k is the maximum number of elements in a node, neglecting the “high key,” which is explained below.)
x <- scannode(u, A) denotes the operation of examining the tree node in memory block A for value u and returning the appropriate pointer from A (into x).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
procedure search(u) current <- root; A <- get(current); while current is not a leaf do begin current <- scannode(u, A); A <- get(current) end;
while t <- scannode(u, A) = link ptr of A do begin current + t ; A <- get(current) end;
if v is in A then done “success” else done “failure”
将值 u 插入叶子节点时,可能需要对该节点进行分裂(当节点不安全时)。 在这种情况下,我们对节点进行分裂(如图 8 所示),用两个新节点 a’(a 的新版本,写回同一磁盘页面)和 b’ 替换原来的节点 a。节点 a’ 和 b’ 的内容与原节点 a 相同,只是增加了值 u。随后,我们沿着先前记录的搜索路径回溯树的上层,在叶子节点的父节点中插入新节点 b’ 的条目以及 a’ 的新 high key。
死锁的避免是由锁定方案的良序性(well-ordering)所保证的,如下所示。 需要注意的是,当我们沿树向上回溯时,由于节点可能被分裂,我们必须插入新指针的节点可能并不是下降过程中经过的那个节点。换句话说,我们在下降过程中使用的旧节点可能已经被分裂;此时,正确的插入位置就在原预期插入位置右侧的某个节点。我们通过 link 指针 来找到这个节点。
A <- node.insert (A, w, v) denotes the operation of inserting the pointer w and the value v into the node contained in A. u <- allocate(2 newpage for B) denotes the operation of allocating a new page on the disk. The node contained in B will be written onto this page, using the pointer u. “A, B <- rearrange old A, adding ..” denotes the operation of splitting A into two nodes, A and B, in core.
插入(Insert)。该算法负责将一个值 v(以及其关联的记录)插入到树中。当算法结束时,值 v 已成功插入到树中,并且在必要的情况下,算法会在从叶子向上回溯的过程中对相应的节点进行分裂。
procedure insert(v) initialize stack; current <- root; A <- get(current); while current is not a leaf do begin t <- current; current <- scannode( v, A); if new current was not link pointer in A then push(t); A <- get(current); end; lock(current); A <- get(current); move.right; if v is in A then stop “v already exists in tree”; w <- pointer to pages allocated for record associated with v; Doinsertion: if A is safe then begin A <- node.insert(A, w, v); put(A, current); unLock(current); end else begin u <- allocate(1 new page for B); A, B <- rearrange old A, adding v and w, to make 2 nodes, where (link ptr of A, link ptr of B) <- (u, link ptr of old A); y <- max value stored in new A; put(B, u) put(A, current); oldnode <- current; v <- Y; w <- u; current <- pop(stack); lock(current); A <- get(current); move.right; unlock(oldnode); goto Doinsertion end
Move.right. This procedure, which is called by insert, follows link pointers at a given level, if necessary.
1 2 3 4 5 6 7 8
procedure move.right while t <- scannode(u, A) is a link pointer of A do begin lock(t); unlock(current); current <- t; A <- get(current); end
需要注意的是,该过程在向上回溯树时是 逐层进行的。此外,同时最多只会锁定三个节点,而这种情况发生的频率相对较低:仅在插入分裂节点的指针时,需要沿 link 指针向右移动 的情况下才会出现。此时,被锁定的节点包括:
该算法的正确性依赖于以下事实:树结构的任何变化(即任何节点的分裂)都会伴随一个 link 指针。节点分裂时,条目总是被移动到树的右侧,在右侧的新节点可以通过 link 指针被访问到,从而保证树的结构在并发操作下仍然可达且正确。
具体来说,对于任何层级的一个对象(与某个值相关联),我们总能大致知道它的正确插入位置,即我们在该层搜索时经过的“记录节点”。如果该对象的正确插入位置发生了移动,这种移动方式是可预知的:也就是节点分裂向右,留下的 link 指针使得搜索或插入操作仍然能够找到它。因此,从旧的“预期”插入位置开始,始终可以访问到对象的正确插入位置。
注意,在算法中(针对不安全节点),“put(B, u)” 紧接在 “put(A, current)” 之前执行。我们将在下面的引理中证明,这种顺序实际上将两个 put 操作简化为本质上的一次操作。
引理 2. 操作 ‘put(B, u); put(A, current)’ 相当于对树结构的一次修改。 证明. 假设这两个操作分别写入节点 b 和 a。在执行 “put(B, u)” 时,没有其他节点指向正在写入的节点 b,因此该 put 操作对树结构没有影响。现在,当执行 “put(A, current)” 时,该操作修改了 current 指向的节点(节点 a)。修改内容包括将节点 a 的链接指针指向 b。此时,b 已经存在,并且 b 的链接指针指向与 a 的旧版本相同的节点。这样就实现了同时修改 a 并将 b 引入树结构。证毕。
定理 2. 所有 put 操作都能正确地修改树结构。 证明 case 1: 对安全节点执行 “put(A, current)”。该操作只修改树中一个已加锁的节点,因此树的正确性得到保持。 case 2: 对不安全节点执行 “put(B, u)”。该操作不会改变树结构。 case 3: 对不安全节点执行 “put(A, current)”。根据引理,该操作既修改了当前节点(比如 a),又将另一个节点(比如 b,通过 “put(B, u)” 写入)引入树结构。与情况 1 类似,节点 a 在执行 “put(A, current)” 时已加锁。本例的区别在于该节点是不安全的,需要分裂。但根据引理,我们可以通过一次操作完成,保持树结构的正确性。证毕
证明. 考虑进程 P 通过节点 a 的路径。进程 P 在到达节点 a 之前所经过的路径不会被插入进程 I 改变。此外,根据上面的定理 2,进程 I 对树结构所做的任何修改都会产生一个正确的树(well-ording)。因此,进程 P 在 a 节点开始的路径(在时间 t>t′t > t’t>t′)将无论修改如何都能正确执行。证毕。
第 1 部分. 考虑插入进程 I(在时间 t0 修改节点 n)与搜索进程 S(在时间 t′< t0读取节点 n)之间的交互。记 n′ 为修改后的节点。(本节的论证同样适用于另一插入进程 I′与进程 I 交互的情况,且 I′正在执行搜索。)需要考虑的操作顺序是:S 读取节点 n;然后 I 将节点 n 修改为 n′;然后 S 根据 n 的内容继续搜索。 考虑三种插入类型:
Type 1
进程 I 对节点 n 执行一次简单插入。如果 n 是叶子节点,插入进程不会改变任何指针。其结果等同于序列调度中 S 在 I 之前运行的情况。如果 n 是非叶子节点,则在 n 中插入一个指向下一层某节点 m′的指针/值对。假设 m′是通过将 I 分裂为 I′ 和 m′ 创建的。唯一可能的交互是 S 在插入指向 m′ 的指针之前已经获得了指向 I 的指针。此时指向 I 的指针指向了 I′,而 S 将使用 I′中的 link pointer 访问 m′。因此搜索仍然是正确的。
Types 2 and 3
节点 n 在插入过程中被分裂为节点 n1′ 和 n2′。对于叶子节点的情况,搜索在 n 上的结果与在 n1′和 n2′上的结果相同,除了新插入的值 S 无法找到。 如果 n 不是叶子节点,则其下层的某个节点发生了分裂,导致一个新的指针/值对被插入节点 n,从而使 n 本身也分裂。根据归纳法,下层节点的分裂是正确的。根据引理 3,下层节点的搜索也是正确的。因此,我们只需证明节点 n 的分裂是正确的。假设节点 n 分裂为节点 n1′ 和 n2′,它们包含与原节点 n 相同的指针集合,并增加了新插入的节点。则从节点 n 开始搜索,将到达下一层与从 n1′(带有指向 n2′的 link pointer)开始搜索时相同的节点集合。特殊情况是:如果搜索在读取节点 n 时,新插入的指针已经存在,本应沿该指针继续。此时实际跟随的指针位于新指针的左侧,这会将搜索引导到某个节点(假设为 k),它位于新指针指向的节点(假设为 m)左侧。然后沿 k 的 link pointer 最终到达 m,这仍然是正确的结果。(类型 3 的论证与类型 2 相同,只是新条目插入到新创建的半节点中,而不是旧半节点。但这对论证没有影响,因为节点在分裂发生前已被S读取。)
第2部分。接下来我们考虑插入进程 I 与另一个插入进程 I’ 的交互情况。进程 I’ 可能正在搜索用于插入的正确节点、回溯到另一层,或者实际尝试将一个值/指针对插入节点 n。如果 I’ 正在搜索一个用于插入值/指针对的节点,则该搜索行为与普通搜索进程完全相同。因此,证明与上文针对搜索进程的证明相同。
考虑在将某个节点 n 压入栈和回溯时再次访问该节点之间可能发生的情况:该节点可能已经分裂过一次或多次,这些分裂会在节点 n 的“右侧”产生新的节点。
由于节点 n 右侧的所有节点都可以通过 link 指针访问,因此插入算法能够找到适当的位置插入值。
第四部分。如果进程 I’ 试图在节点 n 上进行插入,它会尝试锁定该节点。但进程 I 已经持有节点 n 的锁。最终,I 会释放该锁,I’ 再锁定该节点并将其读入内存。根据上面的引理,该交互是正确的,因为 I’ 的读取发生在 I 的插入之前。节点 n 要么就是插入的正确位置——此时 I’ 会执行插入;要么搜索必须沿节点的 link 指针访问其右兄弟。
LiveLock
我们在此指出,我们的算法并不能完全避免活锁(LiveLock)的可能性(即某个进程无限运行)。 如果一个进程因为不断跟随其他进程创建的 link 指针而无法终止,就可能发生这种情况。 然而,根据以下观察,我们认为在实际实现中这种情况极不可能成为问题。 在多处理器系统中,如果该进程运行在相对非常慢的处理器上,这种情况可能发生。
(1) 在我们所知的大多数系统中,处理器的运行速度大致相当。 (2) 在 B 树中,节点的创建和删除只占很小的比例,因此即使是较慢的处理器,也不太可能因节点的创建或删除而遇到困难(也就是说,它只需要跟随少量的 link 指针)。 (3) 在树的任意给定层上,只能创建固定数量的节点,从而限制了较慢处理器需要“追赶”的量。
一种处理删除操作的简单方法是允许叶子节点中的条目少于 K 个。对于非叶子节点则不需要这样做,因为删除操作仅会移除叶子节点中的键;非叶子节点中的键仅作为其对应指针的上界,它在删除过程中并不会被移除。
因此,为了从叶子节点中删除一个条目,我们对该节点执行的操作与插入操作(尤其是插入情况 1)非常类似。具体来说,我们首先搜索出值 u 所在的节点,然后锁定该节点,将其读入内存,对内存中的副本删除值 u 后再将节点重写回磁盘。有时,这样会导致节点中条目数量少于 K。 该算法的正确性证明与插入操作类似。例如,死锁自由性的证明非常简单,因为删除操作只需要锁定一个节点。对于操作的正确性,如果一个搜索进程在删除值 u 之前读取了节点,它仍然会报告节点中存在 u,这与序列化调度(搜索操作先于删除操作执行)是一致的,因此搜索结果仍然正确。
test=# create table users(id int generated always asidentityprimary key, name text); CREATE TABLE
test=# select oid, relname, relfilenode from pg_class where relname ='users'; oid | relname | relfilenode -------+---------+------------- 40980| users |40980
test=# select c.oid, c.relname, i.indisprimary from pg_class c join pg_index i on c.oid = i.indexrelid where i.indrelid ='users'::regclass and i.indisprimary; oid | relname | indisprimary -------+------------+-------------- 40986| users_pkey | t (1row)
test=# select lp,lp_len,t_data from heap_page_items(get_raw_page('users', 0)); ERROR: block number 0isoutofrangefor relation "users" test=# select*from bt_page_items('users_pkey',1); ERROR: block number 1isoutofrange test=# ^C
test=# select*from bt_page_items('users_pkey',1); itemoffset | ctid | itemlen | nulls | vars | data | dead | htid | tids ------------+-------+---------+-------+------+-------------------------+------+-------+------ 1| (0,1) |16| f | f |0100000000000000| f | (0,1) | 2| (0,2) |16| f | f |0200000000000000| f | (0,2) | (2rows)
To build OceanBase from source code, you need to install the C++ toolchain in your development environment first. If the C++ toolchain is not installed yet, you can follow the instructions in this document for installation.
You can check the mysql_port in ./tools/deploy/single.yaml file to see the listening port. Normally, if you deploy with the root user, the OceanBase server will listen on port 10000, and the examples below are also based on this port.
Connect
You can use the official MySQL client to connect to OceanBase:
1
mysql -uroot -h127.0.0.1-P10000
Alternatively, you can use the obclient to connect to OceanBase:
1
./deps/3rd/u01/obclient/bin/obclient -h127.0.0.1-P10000 -uroot -Doceanbase -A