一致性hash
在分布式数据库中,一行数据最终会被写入哪一台机器,取决于系统所采用的数据分布策略。在使用分布键(distribution key)的场景下,这一过程通常由哈希计算精确映射完成。
这个映射过程通常从一个 distribution key(分布键) 开始,经由哈希函数,最终落到某一个具体的数据节点上。
看似简单的映射关系,在系统扩容或缩容时,却会成为分布式系统设计中的一个核心难题。一致性 Hash,正是为了解决这个问题而出现的。
从一个分布式表说起
以一个分布式数据库中的表为例:
1 | CREATE TABLE orders ( |
在这个例子中:
user_id被指定为 distribution key- 数据库会对
user_id计算哈希值 - 哈希值先映射到某个 shard
- shard 再映射到具体的 database node
(shard -> databasenode, 在本文后续省略,直接表示为 数据节点id,即database n)
从这一刻开始,user_id 就决定了这行数据在物理层面“住在哪里”。
最直观的方案:取模 Hash
在多数据节点之间,最容易想到的一种数据分布方式是取模 Hash。
其基本思路非常直接:
- 对
user_id计算哈希值 - 用哈希值对数据库节点数量取模
- 取模结果即为目标数据库节点
示意图如下:
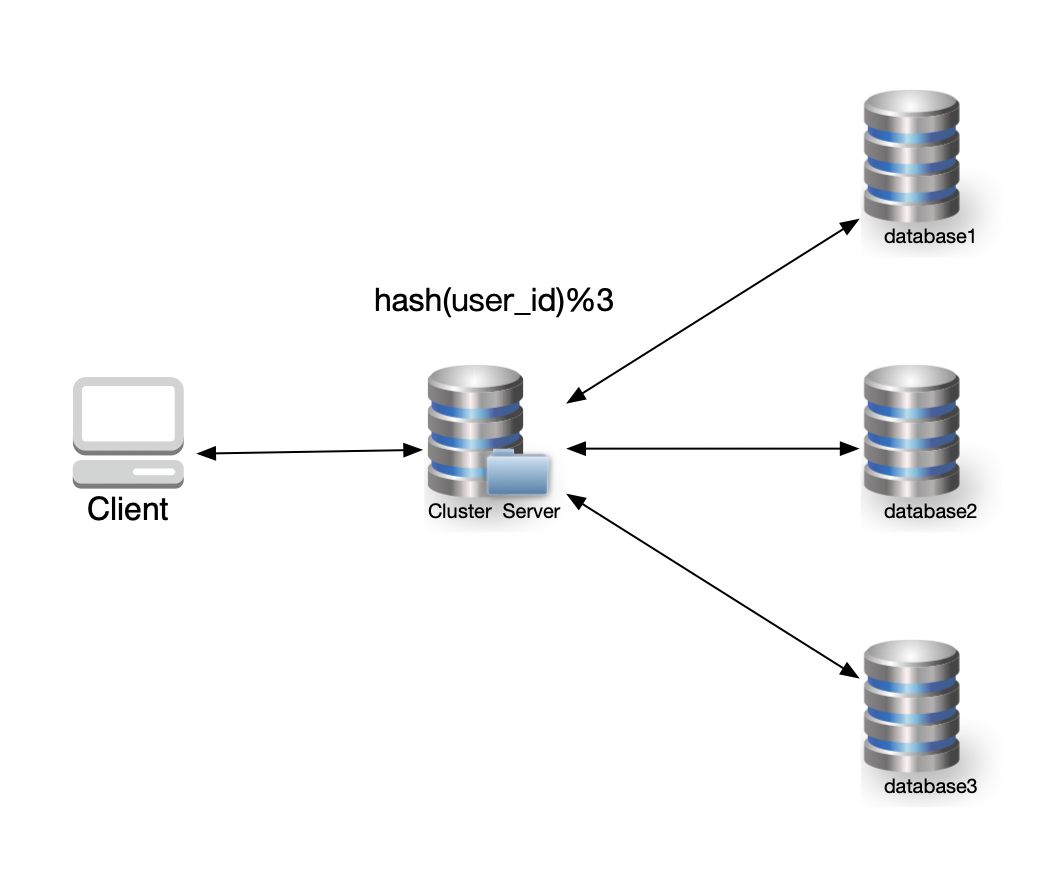
对应的算法可以表示为:
1 | database_id = hash(user_id) % num_of_dbs |
比如,当数据库集群拥有3个数据节点:
假设:
hash(123) = 7
hash(456) = 12
hash(789) = 5
则
1 | user id:123 → 7 % 3 = 1 → Database 1 |
在数据节点数量固定的前提下,这种方式能够较为均匀地分布数据,实现也非常简单。
但问题很快就会出现。
问题一:扩容几乎等于“重来一遍”
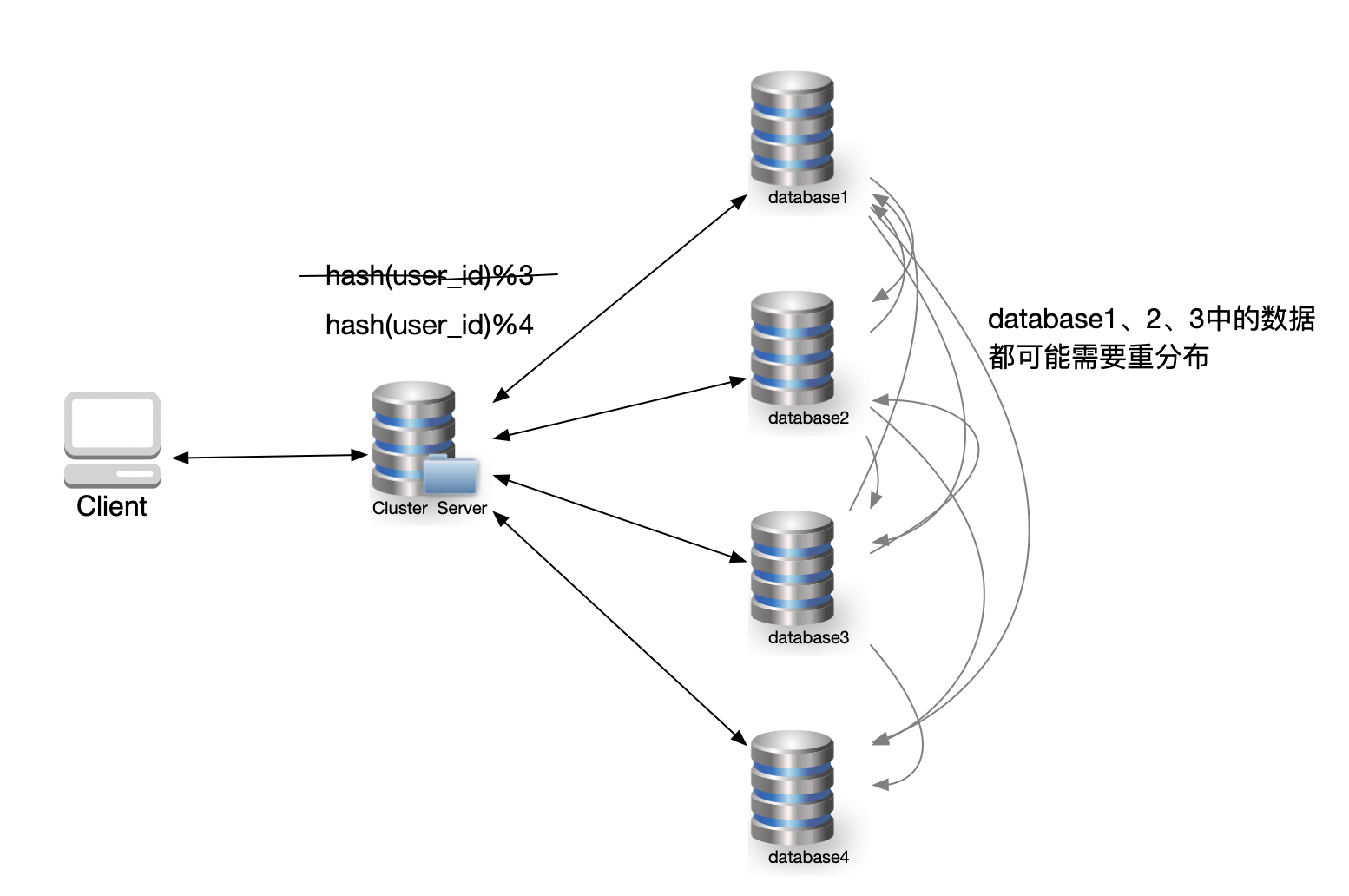
随着业务增长,3 台数据节点已经无法承载当前数据量,需要扩容到 4 台。
算法随之变为:
1 | database_id = hash(user_id) % 4 |
对于新写入的数据来说,这个变化影响不大。但对于已有数据而言,情况就完全不同了。
由于取模基数发生变化,几乎所有 user_id 的映射结果都会改变,意味着:
存量数据需要在节点之间进行大规模重分布。
示意如下:
例如,用户 123 过去映射到 Database 1,但现在:
1 | hash(123) % 4 = 3 (即:7%4) |
这行数据必须从Database 1迁移到 Database 3。
这种迁移不是个别现象,而是系统性问题,代价极其高昂。
对于取模 Hash,当节点从 n 变为 n+1 时,数据迁移率约为 n/(n+1)。这意味着如果从 9 台扩容到 10 台,会有 90% 的数据需要搬家
问题二:缩容同样不可接受
缩容的情况并不会更好。
当某个节点被下线时,取模 Hash 同样会导致大规模数据重新分布,带来:
- 大量数据迁移
- IO 抖动
- 服务不稳定
问题的本质在于:
节点数量一旦发生变化,整个哈希空间的映射关系就被彻底打乱。
为了解决这一问题,我们需要一种在节点变化时“尽量少动数据”的方案。
一致性 Hash 的核心思想
一致性 Hash 的目标很明确:
在添加或删除节点时,尽可能减少需要重新分布的数据量。
其基本做法是:
- 将整个哈希值空间组织成一个虚拟的环
- 哈希空间通常是
0 ~ 2³²−1 - 数据节点和数据本身都映射到这个环上
- 数据沿顺时针方向,落到遇到的第一个节点上
为便于说明,我们将哈希空间简化为 0~100,并假设通过哈希计算,4 个数据库节点在环上大致分布在如下位置:
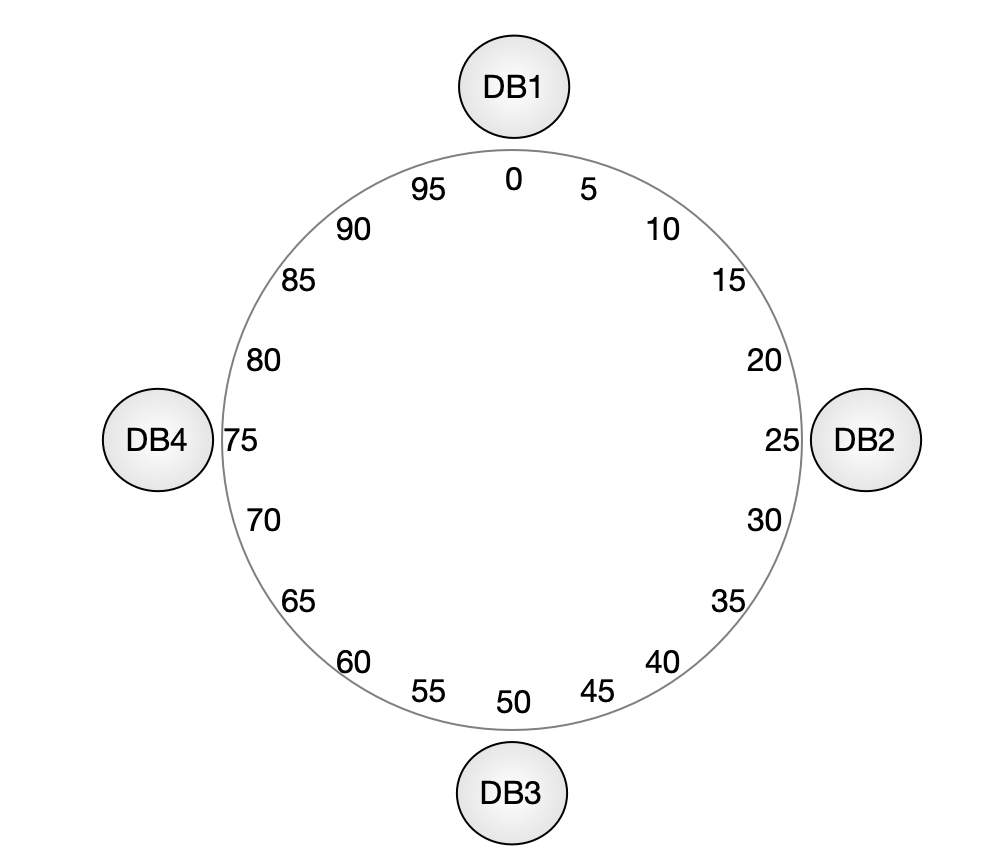
- DB1 → 0
- DB2 → 25
- DB3 → 50
- DB4 → 75
当我们对 user_id 计算哈希后:
- 不再取模
- 而是在环上找到该哈希值
- 顺时针查找第一个数据库节点
扩容时发生了什么?
现在,我们在环上的位置 65 新增一个数据库节点 DB5。
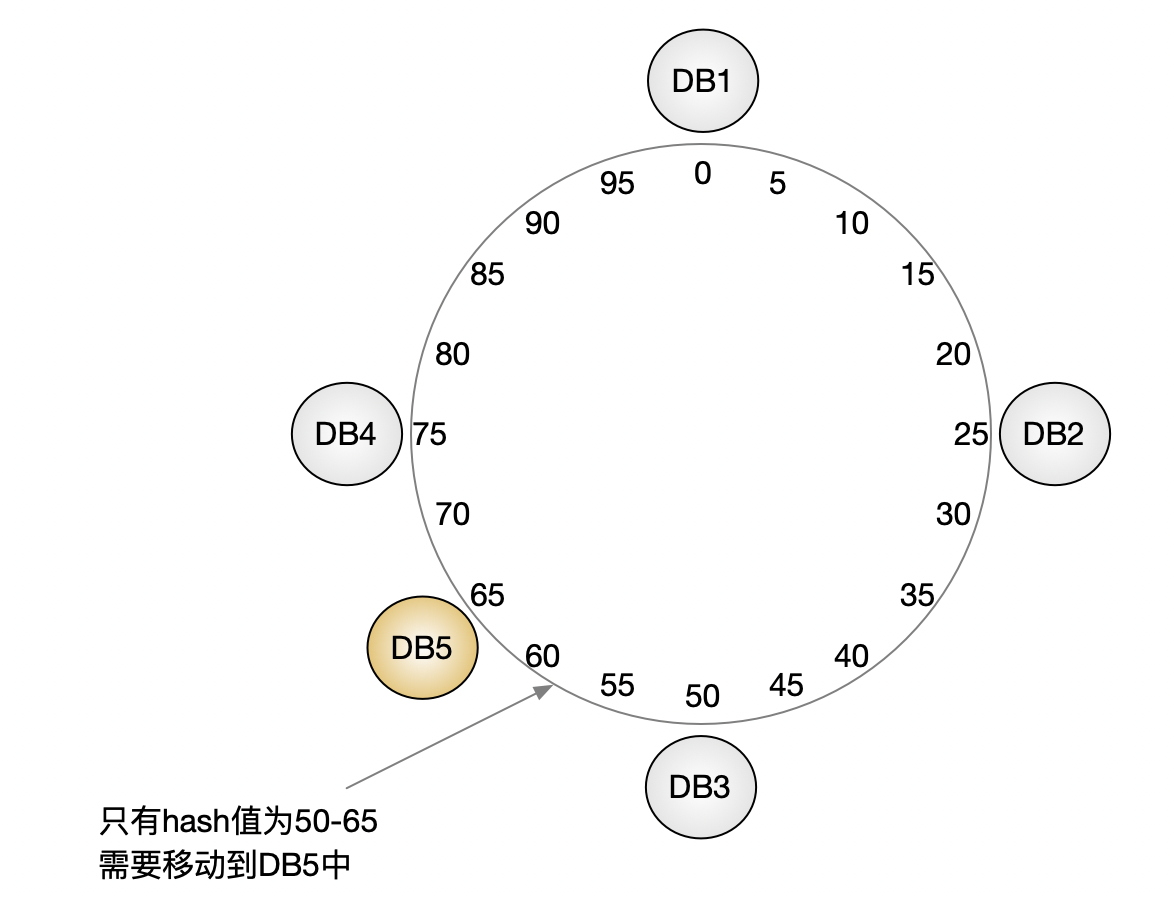
此时:
- 只有哈希值位于
(50, 65]区间的数据需要迁移 - 其他数据完全不受影响
相比取模 Hash,数据迁移范围被大幅缩小。
缩容时的行为
缩容同样遵循相同的规则。
如果移除某个节点,其负责的哈希区间会顺延给下一个节点,而不会影响整个系统的映射关系。
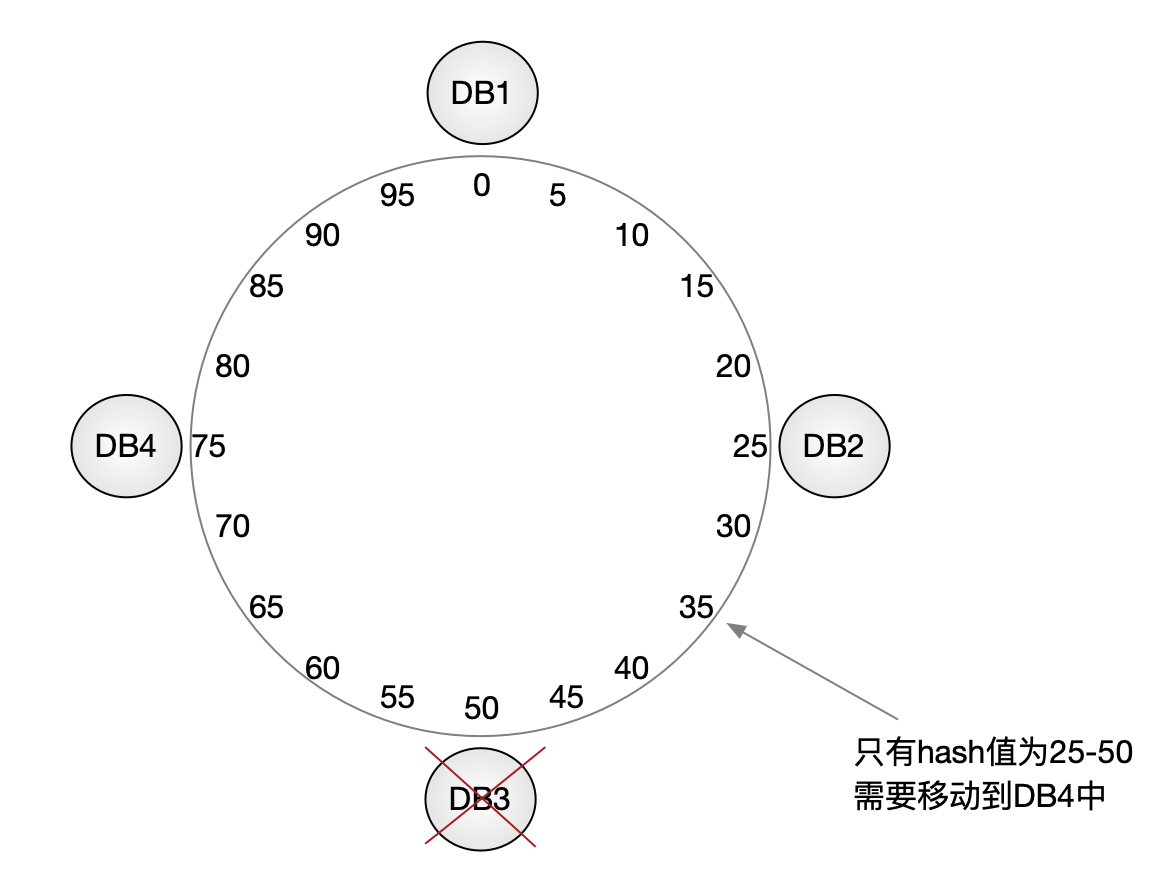
仍然存在的问题:负载不均
到这里,一致性 Hash 看起来已经非常理想了,但在工程实践中还会遇到一个问题:
节点之间的负载可能严重不均衡。
例如,在移除 DB3 的场景中:
原本属于 DB3 的全部数据会被顺延给同一个相邻节点
这可能导致某一台数据库瞬间成为性能瓶颈。
虚拟节点:工程上的关键改进
为了解决负载不均的问题,需要引入 虚拟节点(Virtual Nodes) 的概念。
核心思想是:
一个物理节点,在哈希环上不只占据一个位置。
具体做法是:
- 对同一数据库节点构造多个不同的标识
- 分别计算哈希值
- 将这些位置都映射到同一台物理机器
例如,对于节点 database1,可以构造:
Hash("database1#1")-> pos(VDB1#1)Hash("database1#2")-> pos(VDB1#2)Hash("database1#3")-> pos(VDB1#3)Hash("database1#4")-> pos(VDB1#4)
它们在逻辑上是 4 个独立节点,但在物理上都指向同一台服务器。
示意如下:
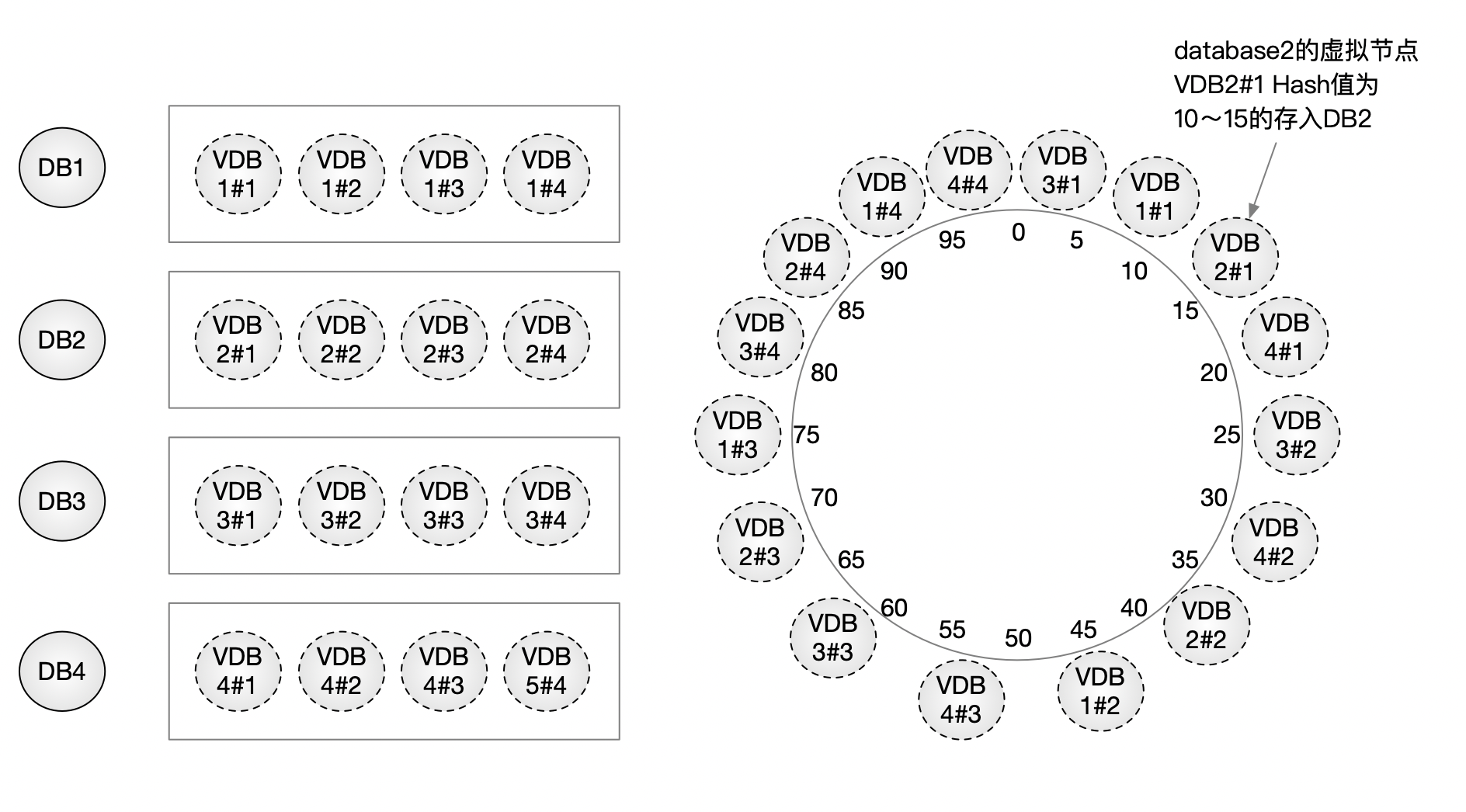
引入虚拟节点后:
- 数据在环上的分布更加均匀
- 单个节点的负载波动被显著降低
- 扩容、缩容时的数据迁移成本进一步下降
这是一致性 Hash 能够在工程实践中落地的关键一步。
总结
一致性哈希的价值不在于分布是否更均匀,而在于节点变化时将重映射控制在最小范围
即:当系统发生变化时,如何控制变化的影响范围
| 特性 | 普通取模哈希 | 一致性哈希 |
|---|---|---|
| 节点变化影响 | 全局映射变化,大规模迁移 | 仅影响 hash 环上的局部区间 |
| 扩容/缩容 | 不支持平滑扩容 | 支持在线、低迁移成本扩容 |
| 数据迁移比例 | 约为 1 − 1/N | 约为 1/N |
| 均衡性 | 天然均匀(前提:hash 好) | 原生不均,通过虚拟节点改善 |
| 典型应用 | 本地分片、静态分区 | 分布式缓存、KV、分布式存储 |