【译】不要给 PostgreSQL 分配过多内存
本文为英文技术博客《Don’t give Postgres too much memory》的中文翻译。
原文作者:Tomas Vondra
原文链接:https://vondra.me/posts/dont-give-postgres-too-much-memory/
本文接近原文直译,仅做结构整理与术语统一,所有观点归原作者所有。
背景:一次“批处理”性能排查的经历
我时不时会被拉去排查一些与批处理(batch processing)相关的问题。
最近越来越常见的一种情况是:这些批处理进程会使用非常大的内存限制,尤其是:
maintenance_work_memwork_mem
我猜不少 DBA 的思路是:
“内存越大越好。”
但他们往往没有意识到,这样做实际上可能会明显拖慢性能。
一个触发问题的实际案例
我用一个在测试 GIN 索引并行构建修复 时遇到的例子来说明这个问题。
这个 bug 本身并不复杂,也不算特别有意思,但它需要一个相当高的 maintenance_work_mem 才能复现 —— 最初的报告里使用了 20GB。
为了验证修复是否有效,我在:
- 不同的
maintenance_work_mem设置 - 不同数量的并行 worker
组合下,反复执行 CREATE INDEX。
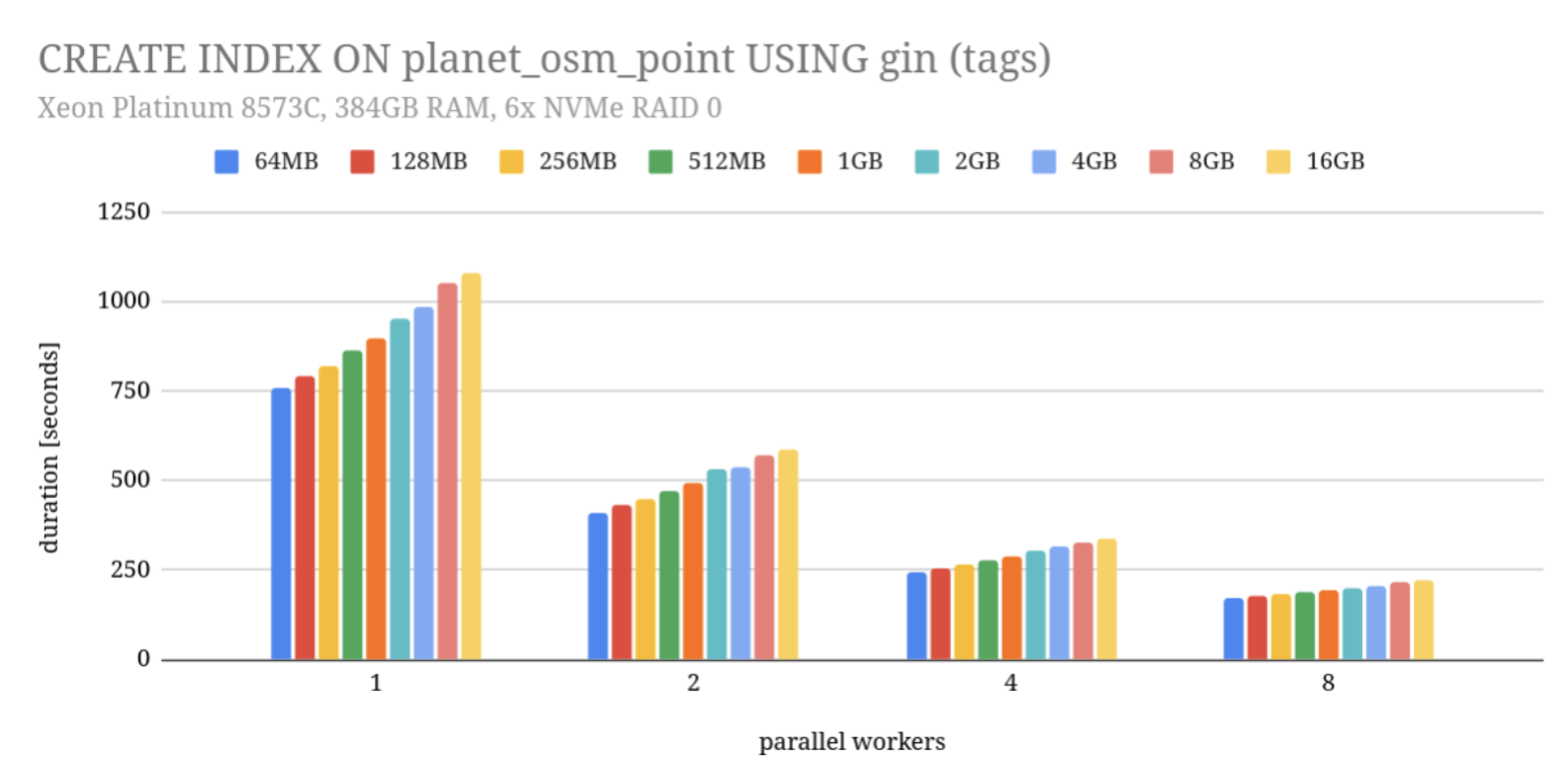
本来的目标只是检查是否还会失败,但我同时也记录了执行时间,并将结果画成了一张图。
测试环境说明
测试运行在 Azure 上的一台 D96v4 实例:
- CPU:Xeon Platinum 8573C
- 内存:384GB
- 存储:6 块 NVMe 组成 RAID0
这意味着:
- 数据基本全部命中缓存
- 瓶颈主要在 CPU,而不是磁盘 I/O
并行化的效果(符合预期)
并行化确实带来了明显收益:
使用 2 个 worker(包括 leader)
→ 性能提升约 1.8 倍
→ 接近理想加速比(因为索引构建的最后阶段仍然是串行的)随着 worker 数量继续增加:
- 加速比逐渐下降
- 例如 8 个 worker 只有约 4.5 倍
这完全符合预期。
反直觉的现象:内存越大,反而越慢
真正令人意外的是图中展示的另一个趋势:
maintenance_work_mem越大,索引构建反而越慢。
具体表现为:
- 从 64MB 增加到 16GB
- 索引构建时间增加了 约 30%
- 并且 无论使用多少并行 worker,这一趋势都一致
为什么会这样?
原因概览
这很可能是多种因素共同作用的结果。
下面我解释两个我认为最重要的原因:
- L3 Cache 的大小限制
- Linux 脏页(dirty page)回写机制
原因一:L3 Cache 的大小限制
系统中的内存并不是“同一种速度”。
在 CPU 内部,存在一小块极快的缓存(L3 Cache),访问延迟非常低。
但这部分内存通常只有 32MB~128MB。
相比之下:
- 主内存(RAM)容量巨大
- 但访问延迟要高一个数量级
索引构建中的内存访问模式
在索引构建过程中,通常会经历以下流程:
- 将数据累积到一个内存缓冲区
- 缓冲区“满了”之后进行处理
- 再合并到最终的索引结构中
对于 GIN 索引 来说,这一步会把条目插入到一个哈希表中,这意味着:
大量随机内存访问
Cache Miss 的代价
一旦这个哈希表的大小超过 L3 Cache,CPU 就不得不频繁访问主内存。
大致的访问代价是:
- L3 Cache:约 20 个 CPU cycle
- 主内存:约 200 个 CPU cycle
也就是说,慢了一个数量级。
更优的策略
因此:
- 将数据拆分成更小的批次处理
- 让工作集尽量能够放进 L3 Cache
往往是更优的策略。
即使需要处理更多批次,总体上仍然可能更快。
推荐阅读:
Ulrich Drepper,《What Every Programmer Should Know About Memory》(2007)
虽然年代久远,但内存层级的基本原理至今没有变化。
原因二:Linux 脏页(dirty page)回写机制
除了 CPU Cache,还有操作系统层面的因素。
当 GIN 的哈希表超过 maintenance_work_mem 限制时,数据会被写入临时文件。
这些文件不需要持久化保证,因此写入时只进入 page cache。
Linux 的脏页控制机制
Linux 内核通过两个阈值控制脏页数量:
vm.dirty_background_ratio- 达到后,后台开始异步回写
vm.dirty_ratio- 达到后,所有写入变成同步写(非常致命)
理想状态下:
后台回写足够快,永远不会触及
vm.dirty_ratio
大批量写入的问题
问题在于:
内核是否有“时间”去完成这些回写。
假设构建哈希表需要累积 8GB 数据,用时 1 分钟:
情况 A:一次性写出
- 1 分钟内几乎不写
- 最后一次性写出 8GB
- 短时间内产生大量脏页
- 极易触发同步写
情况 B:分批写出
- 每 64MB 写一次
- 写操作均匀分布
- 内核有足够时间后台回写
显然后者对系统更加友好。
总结(原文结论)
以上所有分析,**同样适用于 work_mem**。
唯一的区别在于:
maintenance_work_mem- 用于维护操作(
CREATE INDEX、VACUUM等)
- 用于维护操作(
work_mem- 用于普通查询(
hash join、hash aggregate、sort等)
- 用于普通查询(
但底层原理完全一致:
- 哈希表超过 L3 Cache → 性能下降
- 大块内存写入 → 脏页压力 → 可能触发同步写
作者建议
我并不知道 maintenance_work_mem 或 work_mem 的“最佳值”是多少,这也不是这篇文章的重点。
重点在于:
盲目把内存参数调得很大,可能会显著伤害性能。
我的建议是:
- 从比较保守的值开始(例如 64MB)
- 只有在你能明确证明存在收益的情况下,才逐步调高
原文信息
- 原文作者:Tomas Vondra
- 原文地址:https://vondra.me/posts/dont-give-postgres-too-much-memory/