RD-Trees for Full-Text Search
关于全文搜索
全文搜索的目标是从提供的文档集中选择与搜索查询匹配的文档
为了进行搜索,文档会被转换为 tsvector 类型,该类型包含文档中的词素(lexemes)及其在文档中的位置。词素是将单词转换为适合搜索的格式。默认情况下,所有单词都会被标准化为小写,并去除其词尾。
“并去除其词尾”指的是在全文搜索中,对单词进行词干提取(stemming)或词形归一化(normalization)的过程。具体来说,这是将单词的词尾(如英语中的复数、时态、词性变化等)去除,提取出单词的词干(stem)或基本形式,以便在搜索时能够匹配同一词根的不同变体。例如:单词“running”、“ran”和“runs”都源自同一词根“run”。在全文搜索的处理中,这些单词可能会被归一化为“run”,即去除词尾变化,保留词干。搜索“run”时,系统不仅会匹配“run”,还会匹配“running”、“ran”和“runs”等形式,因为它们都被归一化为相同的词干“run”。
1 | demo=# SET default_text_search_config = english; |
所谓的停用词(如“the”或“from”)会被过滤掉:这些词被认为出现频率过高,搜索它们无法返回有意义的搜索结果。当然,所有这些转换都是可以配置的。
查询由另一种类型表示:tsquery。任何查询都包含一个或多个通过逻辑连接符连接的词素:&(与)、|(或)、!(非)。你还可以使用括号来定义操作符的优先级。
1 | demo=# SELECT to_tsquery('wind & (comes | goes)'); |
全文搜索中唯一使用的操作符是匹配操作符 @@:
1 | demo=# SELECT amopopr::regoperator, oprcode::regproc, amopstrategy FROM pg_am am |
该操作符判断文档是否满足查询条件。以下是一个示例:
1 | demo=# SELECT to_tsvector('Where the wind comes from, where the wind goes') @@ to_tsquery('wind & coming'); |
这绝不是对全文搜索的详尽描述,但这些信息应足以理解索引的基础知识。
Indexing tsvector Data
为了实现快速的全文搜索,必须使用索引来支持。索引的对象不是文档本身,而是 tsvector 值。这里有两种选择:一种是在表达式上构建索引并进行类型转换,另一种是添加一个单独的 tsvector 类型列并对该列进行索引。第一种方法的优点是不会浪费空间来存储 tsvector 值,因为这些值实际上并不需要直接存储。但这种方法比第二种方法慢,因为索引引擎需要重新检查访问方法返回的所有堆元组。这意味着对于每个重新检查的行,都需要再次计算 tsvector 值,而且正如我们很快会看到的,GiST 索引会重新检查所有行。
让我们构建一个简单的示例。我们将创建一个包含两列的表:第一列存储文档,第二列存储 tsvector 值。我们可以使用触发器来更新第二列,但更方便的做法是直接将该列声明为生成列。
1 | CREATE TABLE ts( |
在上面的例子中,我使用了带有单一参数的 to_tsvector 函数,通过设置 default_text_search_config 参数来定义全文搜索配置。这种函数变体的波动性(volatility)类别是 STABLE,因为它隐式依赖于参数值。但在这里,我使用了另一种变体,显式指定配置;这种变体是 IMMUTABLE,可以用于生成表达式。
我们插入几行数据
1 | demo=# INSERT INTO ts(doc) VALUES |
因此,R 树不适合用于索引文档,因为边界框(bounding box)的概念对文档没有意义。因此,使用了其 RD 树(俄罗斯套娃,Russian Doll)变体。RD 树不使用边界框,而是使用边界集(bounding set),即一个包含其所有子集元素的集合。对于全文搜索,这样的集合包含文档的词素(lexemes),但在一般情况下,边界集可以是任意的。
在索引条目中表示边界集有几种方法。最简单的一种是列举集合中的所有元素。如下图所示
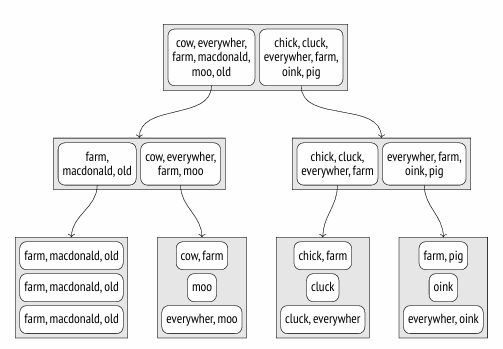
为了找到满足 DOC_TSV @@ TO_TSQUERY(‘COW’) 条件的文档,我们需要深入到那些已知包含“cow”词素的子节点的节点。
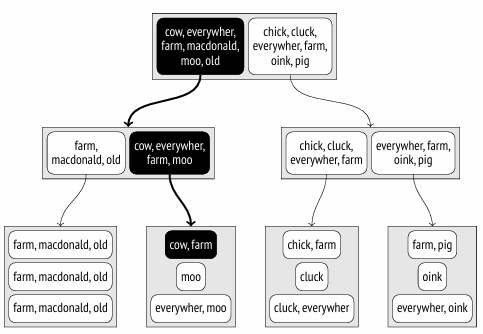
这种表示方式的问题显而易见。文档中的词素数量可能非常庞大,而页面大小是有限的。即使单个文档的独特词素数量不算太多,在树的较高层级中,它们的联合集仍然可能变得过大。
全文搜索使用了另一种解决方案,即更紧凑的签名树(signature tree)。对于那些熟悉布隆过滤器(Bloom filter)的人来说,这种解决方案应该很熟悉。
每个词素可以由其签名(signature)表示:一个特定长度的位字符串,其中只有一位被置为 1。置为 1 的位由词素的哈希函数决定。
文档的签名是对该文档中所有词素签名的按位或(bitwise OR)操作结果。

这种方法的优点显而易见:索引条目大小相同且相当小,因此索引非常紧凑。但也存在一些缺点。首先,无法执行仅索引扫描(index-only scan),因为索引不再存储索引键,每个返回的 TID(行标识)都必须通过表进行重新检查。此外,准确性也会受到影响:索引可能返回许多误报(false positives),这些误报需要在重新检查阶段过滤掉。
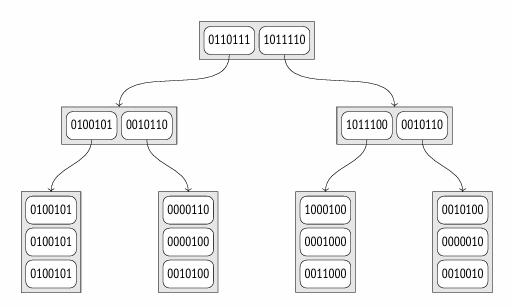
让我们再次看看 DOC_TSV @@ TO_TSQUERY(‘COW’) 条件。查询的签名(signature)以与文档相同的方式计算;在这个特定情况下,其签名等于 0000010。一致性函数(consistency function)必须找到所有签名中具有相同位被置位的子节点。
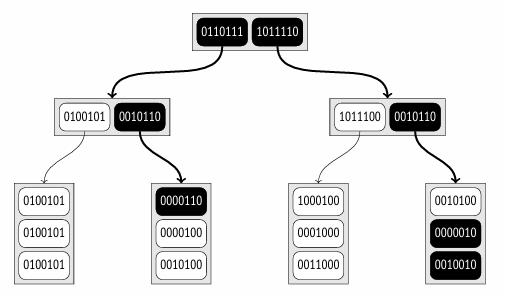
与前面的例子相比,这里需要扫描更多的节点,因为存在误报(false-positive)命中。由于签名的容量有限,在大型集合中,某些词素必然会具有相同的签名。在这个例子中,这样的词素是“cow”和“oink”。这意味着一个签名可能匹配多个不同的文档;在这里,查询的签名对应于三个文档。
误报会降低索引的效率,但不会以任何方式影响其正确性:因为假阴性(false negatives)被保证排除,所以不会遗漏所需的值。
显然,签名的实际大小要大得多。默认情况下,签名占用 123 字节(992 位),因此冲突的概率远低于本例中所示。如果需要,可以使用操作符类参数进一步将签名大小增加到大约 2000 字节。
1 | CREATE INDEX ... USING gist(column tsvector_ops(siglen = 1024)); |
此外,如果值足够小(略小于页面大小的 1/16,对于标准页面大约是 500 字节),tsvector_ops 操作符类会在索引的叶子页面中存储 tsvector 值本身,而不是它们的签名。
为了了解索引在真实数据上的工作方式,我们可以使用 pgsql-hackers 邮件列表存档。该存档包含 356,125 封电子邮件,包括发送日期、主题、作者姓名和正文文本。让我们添加一个 tsvector 类型的列并构建索引。在这里,我将三个值(主题、作者和正文文本)组合成一个单一的向量,以展示文档可以动态生成,而不必存储在单一列中。
1 | ALTER TABLE mail_messages ADD COLUMN tsv tsvector GENERATED ALWAYS AS ( to_tsvector( |
在填充该列(tsv)的过程中,一些特别长的词因为长度太大被过滤掉了。但一旦索引构建完成,就可以用于搜索查询了。
1 | demo=# EXPLAIN (analyze, costs off, timing off, summary off) SELECT * |
除了满足条件的 898 行之外,访问方法还返回了另外 7852 行,这些行需要后续通过回检(recheck)来过滤。如果我们增加签名容量(signature capacity),准确性(也就是索引效率)会提高,但索引的大小也会随之增加。
1 | demo=# DROP INDEX mail_messages_tsv_idx; |
Properties
我已经展示了访问方法的属性,其中大多数在所有操作符类中都是相同的。但是下面两个列级别的属性值得一提:
1 | demo=# SELECT p.name, pg_index_column_has_property('mail_messages_tsv_idx', 1, p.name) |
现在不可能进行 Index-only 扫描了,因为无法从签名中恢复出原始值。
不过在这个特定的场景下这是完全可以接受的:
tsvector 值只是用于搜索,我们真正需要的是文档本身(也就是实际的数据行)。
对于 tsvector_ops 类来说,也没有定义排序操作符
参考书目
- Egor Rogov, PostgreSQL 14 Internals, https://postgrespro.com/community/books/internals