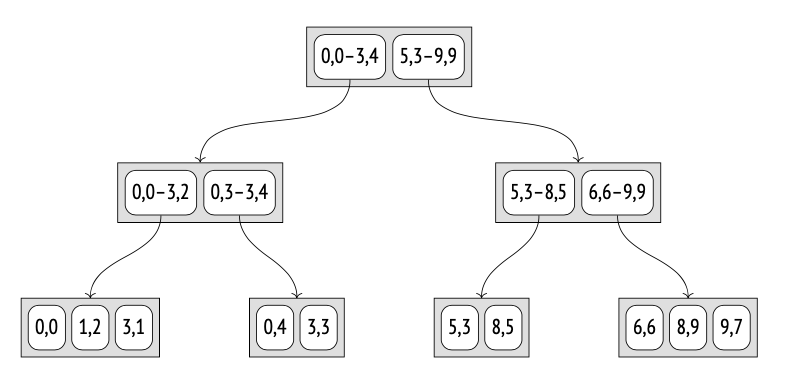
R-tree for points
第一个示例涉及在平面上对点(或其他几何形状)进行索引。常规的B树无法用于这种数据类型,因为点没有定义比较运算符。显然,我们可以自己实现这样的运算符,但几何形状需要索引支持完全不同的操作。我将只讨论其中的两种:搜索特定区域内包含的对象和最近邻搜索。
R树在平面上绘制矩形;这些矩形合起来必须覆盖所有被索引的点。一个索引条目存储边界框,谓词可以定义如下:点位于该边界框内。
R树的根节点包含若干个大矩形(这些矩形可能会有重叠)。子节点包含较小的矩形,这些矩形适合其父节点;它们一起覆盖所有底层的点。
叶节点应该包含被索引的点本身,但GiST要求所有条目具有相同的数据类型;因此,叶节点的条目也由矩形表示,这些矩形被简化为点。
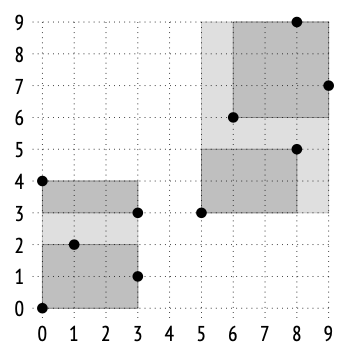
为了更好地可视化这种结构,我们来看一个基于机场坐标构建的R树的三个层次。在这个例子中,我已将演示数据库的机场表扩展到五千行。同时我还降低了fillfactor值使树的层次更深。默认值会给我们一个单层树。
1 | demo=# CREATE TABLE airports_big AS select * from airports_data; |
在顶层,所有点都被包含在几个(可能部分重叠的)边界框中。
在下一层,大矩形被分割成较小的矩形。
最后,在树的底层,每个边界框包含的点数量与单个页面所能容纳的数量相同。
该索引使用point_ops操作符类,这是点数据唯一可用的操作符类。
矩形和其他几何形状可以以相同的方式进行索引,但索引存储的不是对象本身,而是其边界框。
Page Layout
可以通过 pageinspect 插件来学习Gist页
和B-Tree索引不同,Gist没有metapage,0号page就是gist的root节点。如果root节点分裂了,老root节点会被move到一个(或多个)单独的页,新root节点取代其位置
root页的内容如下:
1 | demo=# SELECT ctid, keys FROM gist_page_items(get_raw_page('airports_gist_idx', 0), 'airports_gist_idx' ); |
To extract more detailed information, you can use the gevel extension,which is not included into the standard PostgreSQL distribution.
Operator Class
This query retrieves the list of support functions used by the point_ops operator class in a GiST (Generalized Search Tree) index within a PostgreSQL database
1 | demo=# SELECT amprocnum, amproc::regproc |
必需的函数:
1 consistency function used to traverse the tree during search(检查查询条件是否与索引条目一致)
2 union function that merges rectangles计算边界框的并集)
5 penalty function used to choose the subtree to descend to when inserting an entry (计算插入新条目的代价)
6 picksplit function that distributes entries between new pages after a page split(决定节点分裂方式)
7 same function that checks two keys for equality(比较索引条目是否相同)
point_ops 支持的操作符如下:
1 | demo=# SELECT amopopr::regoperator, amopstrategy AS st, oprcode::regproc, |
操作符的名字通常并不能准确反映其语义,因此这个查询还会显示底层函数的名称和它们的描述。无论具体形式如何,这些操作符都处理几何对象之间的相对位置关系(如在左侧、右侧、上方、下方、包含、被包含)以及它们之间的距离。
与 B-tree 相比,GiST 提供了更多的策略(strategy)。一些策略号在多种类型的索引中是通用的,而另一些则是通过公式计算出来的(例如,策略号 28、48 和 68 实际上代表相同的策略:对矩形、多边形和圆形来说都是“被包含”)。此外,GiST 还支持一些已经过时的操作符名称(例如 <<| 和 |>>)。
一个操作符类(operator class)可能只实现了部分可用的策略。举个例子:点类型的操作符类不支持“包含”这个策略,但这个策略在那些具有可度量面积的几何体操作符类(如 box_ops、poly_ops 和 circle_ops)中是可用的。
Search for Contained Elements
一个典型的可以通过索引加速的查询是返回指定区域内的所有点。例如,我们来查找距离莫斯科中心一度以内的所有机场:
1 | demo=# SELECT airport_code, airport_name->>'en' |
我们可以通过下图所示的一个简单示例来更仔细地查看这个操作符
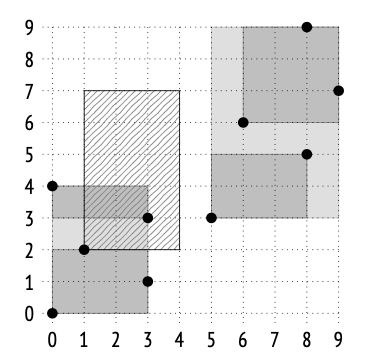
如果以这种方式选择边界框,索引结构将如下所示:
包含操作符 <@ 用于判断某个点是否位于指定矩形内部。对于该操作符,其一致性函数(consistency function)会在索引条目的矩形与指定矩形有任何重合点时返回“是”。这意味着,对于叶子节点中的索引条目(它们通常是退化为点的矩形),该函数实际上是在判断这个点是否被指定的矩形所包含。
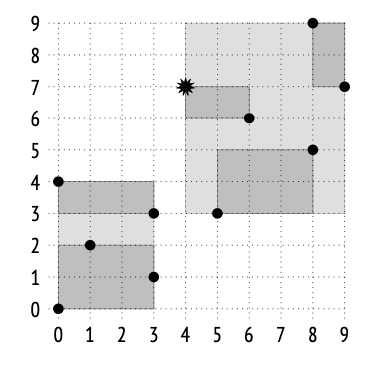
例如,假设我们要查找位于矩形 (1,2)–(4,7) 内部的点,该矩形在下图中以阴影表示:
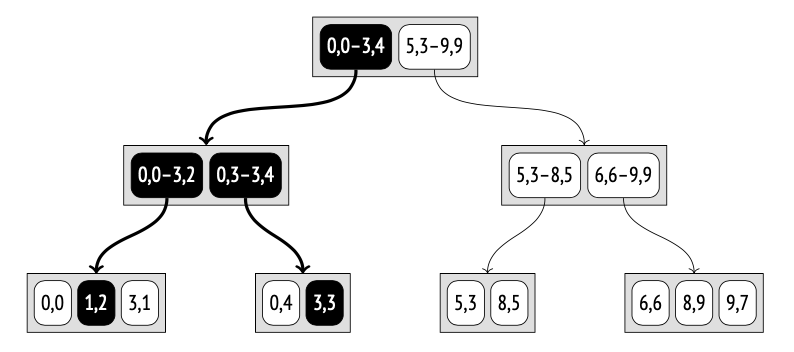
搜索从根节点开始。目标矩形与索引项 (0,0)–(3,4) 有重叠,但与 (5,3)–(9,9) 没有重叠,这意味着我们不需要进入第二棵子树。
在下一层中,目标矩形与 (0,3)–(3,4) 有重叠,并且与 (0,0)–(3,2) 有接触(边界相交),所以我们需要检查这两个子树。
一旦到达叶子节点,我们只需遍历它们包含的所有点,并返回那些满足一致性函数的点
B-tree 的搜索总是只选择一个子节点进行查找。而 GiST 的搜索可能需要扫描多个子树,特别是当它们的边界框(bounding boxes)发生重叠时。
Nearest Neighbor Search
大多数索引支持的操作符(例如上一个例子中的 = 或 <@)通常被称为搜索操作符,因为它们在查询中定义了搜索条件。这类操作符是谓词,即它们返回一个逻辑值(真或假)。
但还有一类是排序操作符,它们返回的是参数之间的距离。这类操作符通常用于 ORDER BY 子句中,并且一般由具有 Distance Orderable 属性的索引所支持。该属性允许你快速找到指定数量的最近邻。这种类型的搜索被称为 k-NN(k 最近邻搜索)。
例如,我们可以查找最接近 Kostroma 的 10 个机场:
1 | demo=# SELECT airport_code, airport_name->>'en' |
由于索引扫描是逐个返回结果,并且可以在任何时刻停止,因此前几个值可以非常快速地获取到。
如果没有索引支持,要实现高效的搜索将非常困难。我们将不得不先查找某个特定区域内的所有点,然后逐步扩大该区域,直到返回所需数量的结果。
这将需要多次索引扫描,更不用说还存在一个难题:如何选择初始区域的大小以及每次扩展的增量。
你可以在系统目录中查看操作符的类型(其中 “s” 表示搜索操作符,”o” 表示排序操作符)。
1 | demo=# SELECT amopopr::regoperator, amoppurpose, amopstrategy FROM pg_am am |
为了支持这类查询,操作符类必须定义一个额外的支持函数:也就是距离函数(distance function),它会在索引项上被调用,用于计算该索引项中存储的值与另一个值之间的距离。
对于表示索引值的叶子节点元素,该函数必须返回与该值之间的距离。
如果是点(point)类型,这个距离就是常规的欧几里得距离,计算公式为:
1 | d = sqrt((x₂-x₁)²+(y₂-y₁)²) |
对于一个内部节点,其距离函数必须返回其所有子叶节点中可能距离的最小值。
由于扫描所有子节点的条目代价较高,该函数可以乐观地低估这个距离(以牺牲效率为代价),但绝不能返回一个较大的值——否则将会破坏搜索的正确性
因此,对于一个由边界框(bounding box)表示的内部节点,其与某个点之间的距离可以按照常规数学意义来理解:
要么是该点到矩形边界的最小距离;要么是 0(如果该点在矩形内部)。
这个值可以在无需遍历矩形中所有子点的情况下轻松计算出来,
并且它保证不会大于矩形中任意一个子点与该查询点之间的实际距离
我们考虑一下寻离点(6,8)最近的3个值
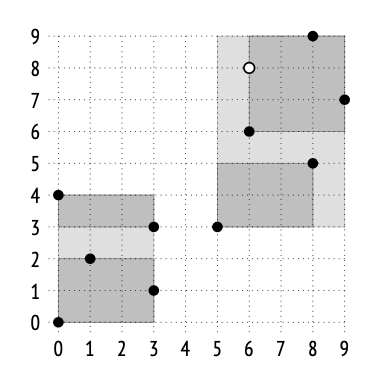
搜索从根节点开始,根节点包含两个边界框(bounding box)。指定查询点到矩形 (0,0)–(3,4) 的距离被计算为到该矩形的角点 (3,4) 的距离,即 5.0。到另一个矩形 (5,3)–(9,9) 的距离为 0.0。(这里我会将所有的距离值四舍五入保留到小数点后一位,这种精度对于这个示例来说已经足够。)
子节点会按照距离增大的顺序被遍历。因此,我们首先进入右子节点,该节点包含两个矩形:(5,3)–(8,5) 和 (6,6)–(9,9)。到第一个矩形的距离是 3.0,到第二个矩形的距离是 0.0。
再次地,我们选择右子树,并进入包含三个点的叶子节点:点 (6,6) 的距离为 2.0,点 (8,9) 的距离为 2.2,点 (9,7) 的距离为 3.2。
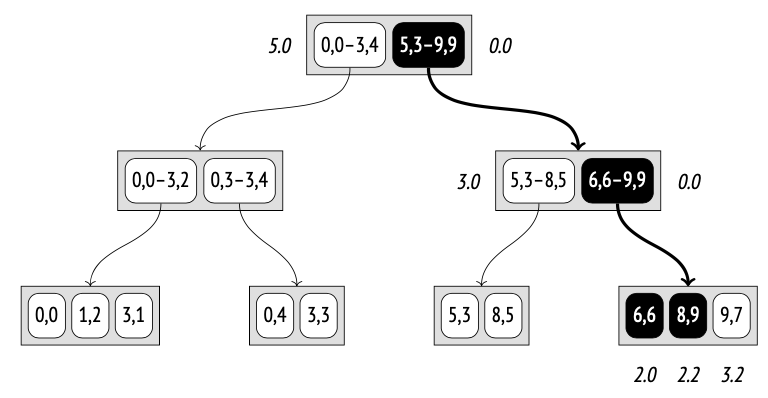
因此,我们已经找到了前两个点:(6,6) 和 (8,9)。但该节点中的第三个点距离(查询点)要大于矩形 (5,3)–(8,5) 的距离。
所以我们需要进入左子节点,该节点包含两个点。到点 (8,5) 的距离是 3.6, 到点 (5,3) 的距离是 5.1。结果发现,之前那个子节点中的点 (9,7) 比左子树中的任何点都更接近查询点 (6,8),因此我们可以将它作为第三个返回结果。
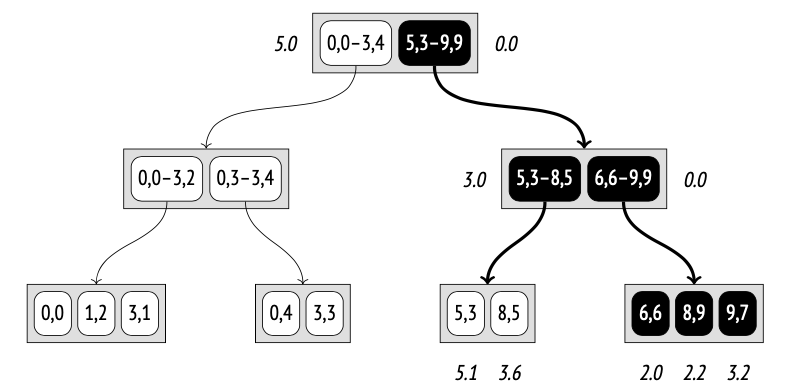
这个例子说明了内部条目的距离函数必须满足的要求。由于到矩形 (5,3)–(8,5) 的距离减小(3.0 而不是 3.6),导致需要额外扫描一个节点,因此搜索效率下降;不过,算法本身仍然是正确的。
Insertion
当向 R 树中插入一个新键时,用于存放该键的节点是由penalty函数决定的:该节点的边界框(bounding box)大小应尽可能少地增加。
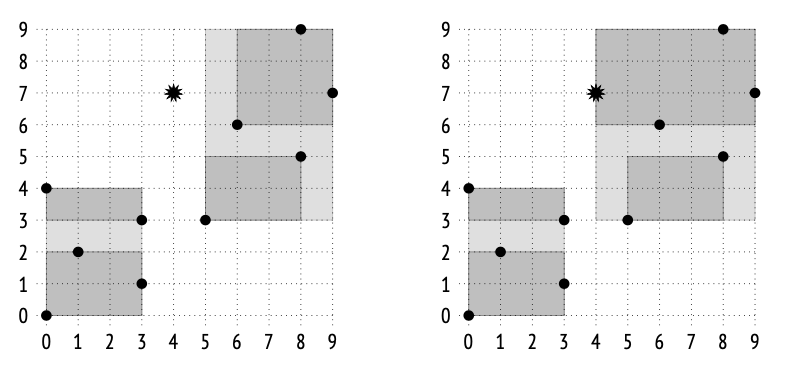
例如,点 (4,7) 将被插入到矩形 (5,3)–(9,9) 中,因为该矩形的面积只需增加 6 个单位;而如果插入到矩形 (0,0)–(3,4),则其面积需要增加 12 个单位。在下一层(叶子层),该点也会按照相同的逻辑被加入到矩形 (6,6)–(9,9) 中。
假设一个页面最多可以容纳三个元素,那么当超出这个限制时,它必须被拆分成两个页面,
并且这些元素需要在新的页面之间重新分配。在这个示例中,分配结果看起来很明显,但在一般情况下,数据的分布并不那么简单。最重要的是,picksplit 函数会尽量减少边界框(bounding box)之间的重叠,目标是获得更小的矩形以及在页面之间均匀分布点。
Exclusion Constraints
GiST 索引也可以用于排除约束(exclusion constraints)。排除约束确保:对任意两条堆表元组来说,它们在某些操作符意义下的指定字段不能彼此匹配。要实现这一点,必须满足以下条件:
- 排除约束(exclusion constraint)必须由索引方法本身支持(即具备 Can Exclude 属性)。
- 所使用的操作符必须属于该索引方法的操作符类(operator class);
- 操作符必须是可交换的:即满足 “a operator b = b operator a” 这个条件。
对于上面提到的 hash 和 btree 访问方法来说,唯一合适的操作符是等于(=)。这实际上使排除约束退化成了唯一约束,因而没有太大实际用途
GiST 方法还支持另外两种适用的策略:
- 重叠(overlapping):由 && 操作符表示
- 相邻(adjacency):由 -|- 操作符表示(该操作符主要用于区间)
我们来试试这个功能:创建一个约束,用于禁止机场之间距离太近。
这个条件可以这样表达:以机场坐标为圆心、指定半径的圆形不得彼此重叠。
1 | demo=# ALTER TABLE airports_data ADD EXCLUDE USING gist (circle(coordinates,0.2) WITH &&); |
当定义一个排除约束(exclusion constraint)时,系统会自动创建一个索引来强制执行该约束。在本例中,这个索引是一个基于表达式的 GiST 索引。
我们来看一个更复杂的例子。假设我们允许机场之间距离很近,但前提是这些机场属于同一个城市。一种可行的解决方案是定义一个新的完整性约束,表达如下:如果两个圆(以机场坐标为圆心)发生重叠(&&),且它们对应的城市名称不同(!=),则这种情况是不允许的。
尝试创建这样的约束会导致一个错误,因为对于 text 数据类型并没有可用的操作符类(operator class)。
1 | demo=# ALTER TABLE airports_data |
虽然 GiST 原生不支持 text 或 int 等有序类型,但借助 btree_gist 扩展,可以让这些类型也具备使用 GiST 进行等值/比较操作的能力,从而用于复杂约束(如排除约束)或混合类型索引。
1 | demo=# CREATE EXTENSION btree_gist; |
该约束已成功创建。现在我们无法添加名为 Zhukovsky 的机场(即使它属于同名城市),
因为它与莫斯科的几个机场之间的距离太近,违反了约束条件。
1 | demo=# INSERT INTO airports_data( |
但是我们可以在莫斯科创建机场
1 | demo=# INSERT INTO airports_data( |
需要注意的是,尽管 GiST 支持大于、小于和等于等操作符,但 B-tree 在这方面效率要高得多,尤其是在访问一段范围值时。因此,只有当确实有其他合理原因需要使用 GiST 索引时,
才有意义使用上面提到的 btree_gist 扩展技巧。
Properties
访问方法属性(Access Method Properties)以下是 GiST 访问方法的属性:
1 | demo=# SELECT a.amname, p.name, pg_indexam_has_property(a.oid, p.name) |
GiST 索引不支持唯一约束(Unique constraints)和排序(sorting)。GiST 索引可以通过额外的 INCLUDE 列来创建。正如我们所知,我们可以在多个列上构建索引,也可以将其用于完整性约束(integrity constraints)。
索引级别属性(Index-level properties)。这些属性是在索引层面定义的。
1 | demo=# SELECT p.name, pg_index_has_property('airports_gist_idx', p.name) |
GiST 索引可以用于聚簇(clusterization)操作。在数据检索方式方面,GiST 支持常规(逐行)索引扫描和位图扫描(bitmap scan)。但 GiST 不支持反向扫描(backward scanning)。
列级别属性(Column-level properties):大多数列属性是在访问方法(access method)级别定义的,并且保持不变。
1 | demo=# SELECT p.name, pg_index_column_has_property('airports_gist_idx', 1, p.name) |
所有与排序相关的属性都是禁用的。
GiST 索引允许 NULL 值存在,但处理效率并不高。一般认为,NULL 值不会扩展边界框(bounding box),所以这些值会被随机插入某个子树中。因此,在查询时需要遍历整棵 GiST 树来查找这些值。
不过,有少数列级属性是依赖于具体操作符类(operator class)的。
1 | demo=# SELECT p.name, pg_index_column_has_property('airports_gist_idx', 1, p.name) |
GiST 索引允许执行索引仅扫描(Index-only scan),因为叶子节点中保留了完整的索引键值。
正如前文所述,某些操作符类(operator class)提供了用于最近邻搜索的距离操作符。
对于 NULL 值,距离计算结果为 NULL,这种情况下这些值会排在最后返回(类似 B-tree 中的 NULLS LAST 语法)。
然而,对于范围类型(range types)而言,并不存在“距离操作符”(因为它们表示的是线段,也就是线性几何体,而不是面状几何体)。所以,当索引建立在这些类型上时,上述性质会有所不同。
1 | demo=# CREATE TABLE reservations(during tsrange); |
参考书目
- Egor Rogov, PostgreSQL 14 Internals, https://postgrespro.com/community/books/internals