WAL设置
配置checkpoint
checkpoint持续时间(更准确地说,是将脏缓冲区写入磁盘所需的时间)由参数 checkpoint_completion_target 决定。该参数的值表示checkpoint 期间的 I/O 分布目标,是一个比例。避免将该参数设置为 1:否则可能会导致下一个checkpoint启动时,上一个checkpoint尚未完成。虽然不会发生灾难性的后果(因为同一时间只能执行一个checkpoint),但正常运行可能仍会受到干扰。
在配置其他参数时,我们可以采用以下方法。首先,确定在两个相邻checkpoint之间应存储的 WAL 文件的合理体积。这个体积越大,系统开销就越小,但它仍然会受到可用磁盘空间和可接受的恢复时间的限制。
为了估算在正常负载下生成这一体积所需的时间,你需要记录初始的 insert LSN,并定期检查它与当前 insert 位置之间的差值
我们将前面计算出的数值视为checkpoint之间的典型间隔,因此将其用作 checkpoint_timeout 参数的值。默认设置往往偏小,通常会将其增加,例如设置为 30 分钟。
但也很可能(甚至可以说是很常见)负载会在某些时候升高,从而导致在这个时间间隔内生成的 WAL 文件体积过大。在这种情况下,必须更频繁地执行checkpoint。为了设置这样的触发机制,我们通过 max_wal_size 参数来限制恢复时所需的 WAL 文件总量。当超过这个阈值时,服务器会额外执行一次checkpoint。
恢复所需的 WAL 文件包含了上一个已完成checkpoint和当前尚未完成检查点的所有记录。因此,为了估算这些文件的总体积,应将计算出的检查点之间的 WAL 大小乘以
1 + checkpoint_completion_target。
在 PostgreSQL 11 版本之前,系统会保留两个已完成checkpoint所对应的 WAL 文件,因此估算恢复所需 WAL 总体积的倍数是:2 + checkpoint_completion_target
按照这种方式,大多数checkpoint会按计划执行,即按照 checkpoint_timeout 设置的时间间隔执行一次;但如果系统负载增加,导致生成的 WAL 文件大小超过 max_wal_size 的设定值,就会提前触发一次checkpoint。
系统还会定期将实际进度与预期数值进行比较,以监控写入进度是否达标。
实际进度由已处理的缓存页所占的比例来定义。
按时间计算的预期进度是指已过去的时间占比,其前提假设是checkpoint必须在 checkpoint_timeout × checkpoint_completion_target 的时间内完成。
按大小计算的预期进度是指已写入的 WAL 文件所占的比例,其总量根据 max_wal_size × checkpoint_completion_target 来估算。
如果脏页提前写入磁盘,checkpointer 进程会暂停一段时间;如果在时间或数据大小的任何一个参数上出现延迟,它会尽快赶上进度。由于同时考虑了时间和数据大小,PostgreSQL 能够用同一套机制来管理定时checkpoint和按需checkpoint。
一旦checkpoint完成,不再需要用于恢复的 WAL 文件将被删除;不过,系统会保留若干文件(总大小不超过 min_wal_size),用于重复利用,并通过重命名的方式保留。
这种重命名机制减少了频繁创建和删除文件所带来的开销;如果你不需要这个功能,可以通过参数 wal_recycle 将其关闭。
下图展示了在正常情况下,磁盘上 WAL 文件大小的变化趋势
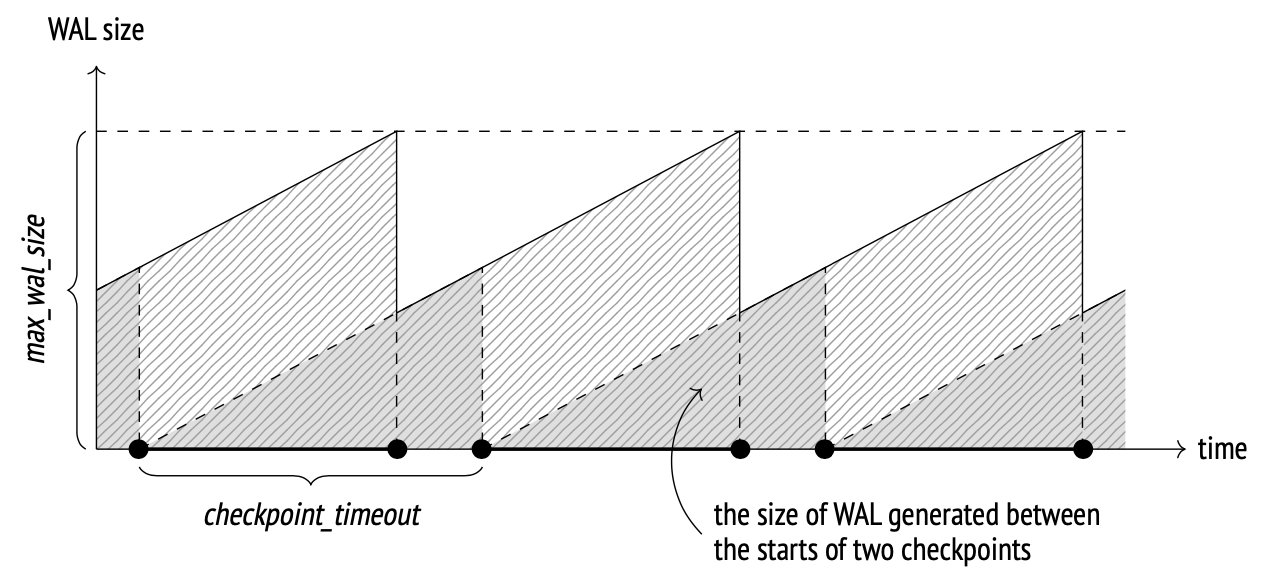
需要注意的是,磁盘上实际的 WAL 文件大小可能会超过 max_wal_size 的设定值,原因包括:
- max_wal_size 参数只是一个期望目标值,而不是严格限制。如果负载突然上升,写入速度可能会落后于计划,导致 WAL 文件积压。
- 尚未被复制或归档的 WAL 文件,服务器无权删除。如果启用了流复制或持续归档功能,必须持续监控这些机制,否则非常容易导致磁盘空间耗尽。
- 你可以通过配置 wal_keep_size 参数来预留一定的磁盘空间用于存储 WAL 文件,以避免这些问题带来的风险。
参考书目
- Egor Rogov, PostgreSQL 14 Internals, https://postgrespro.com/community/books/internals